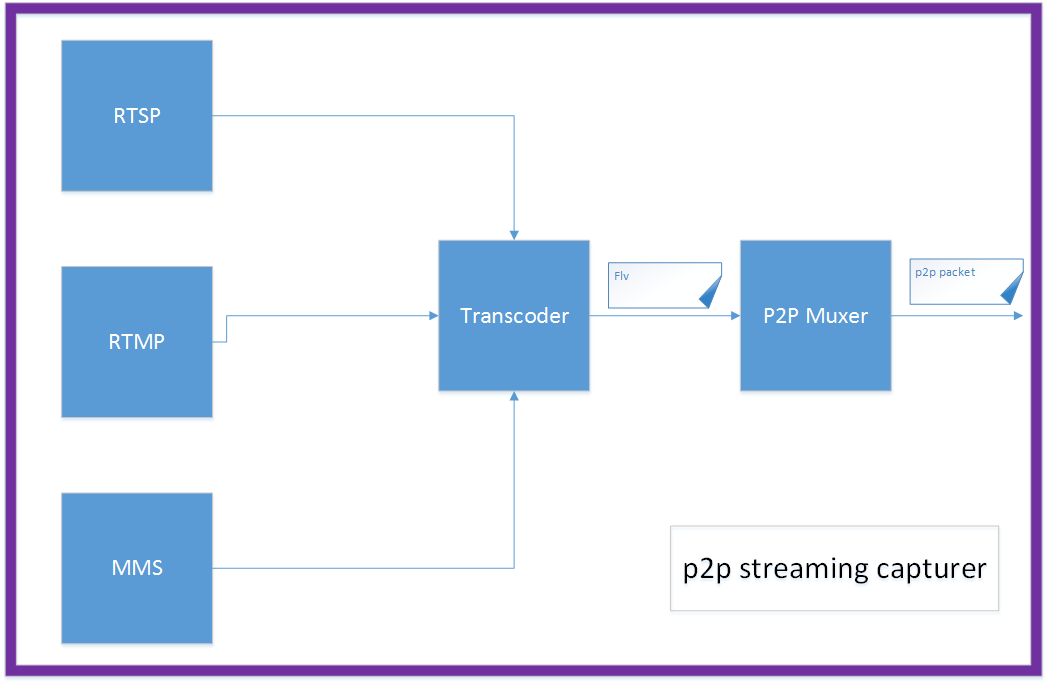
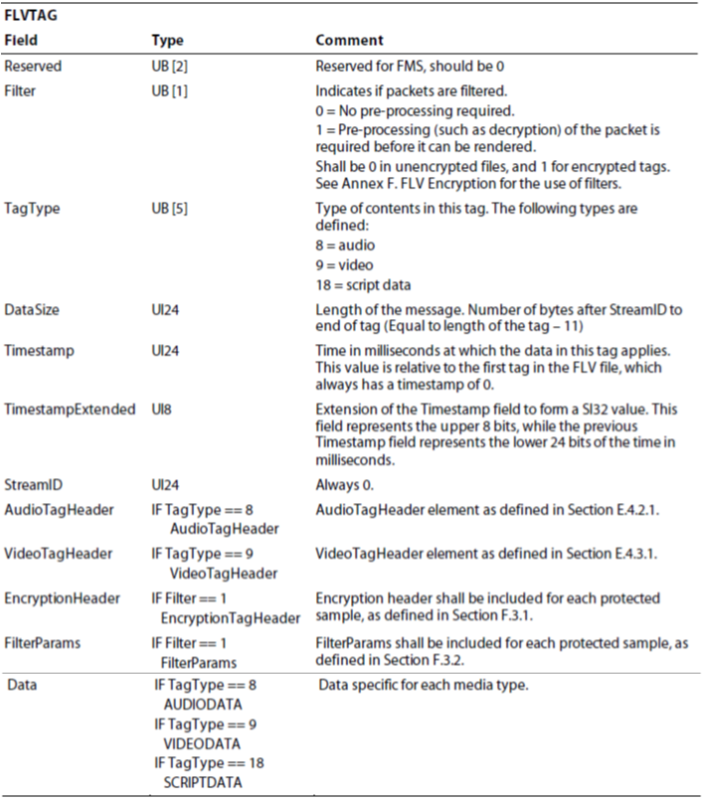
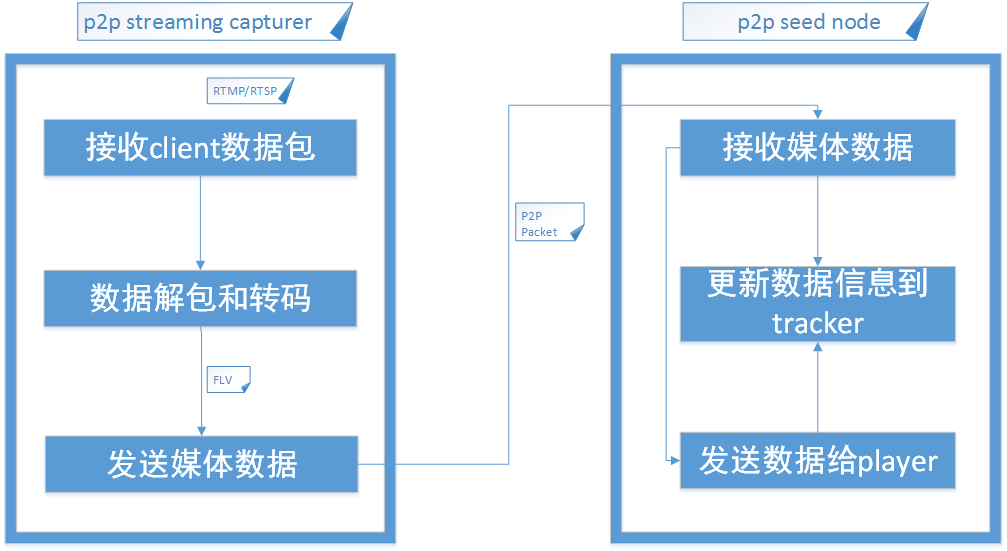
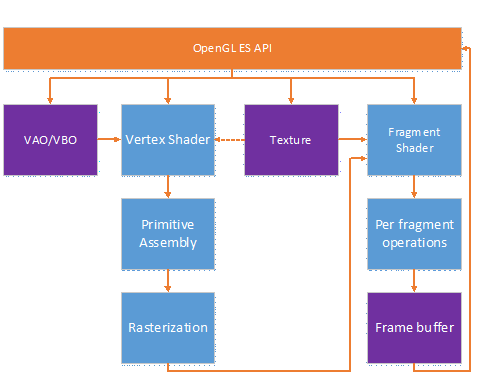
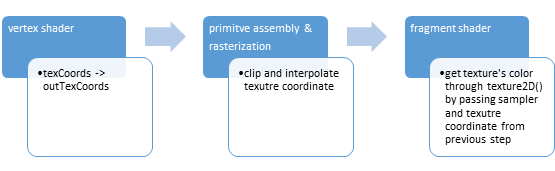
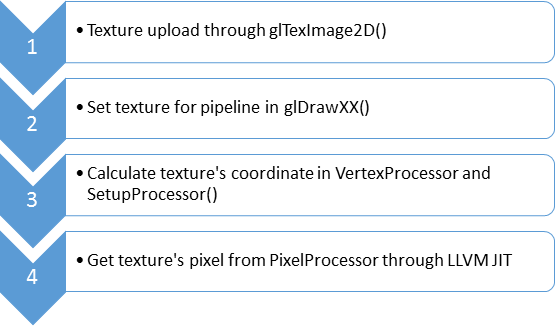
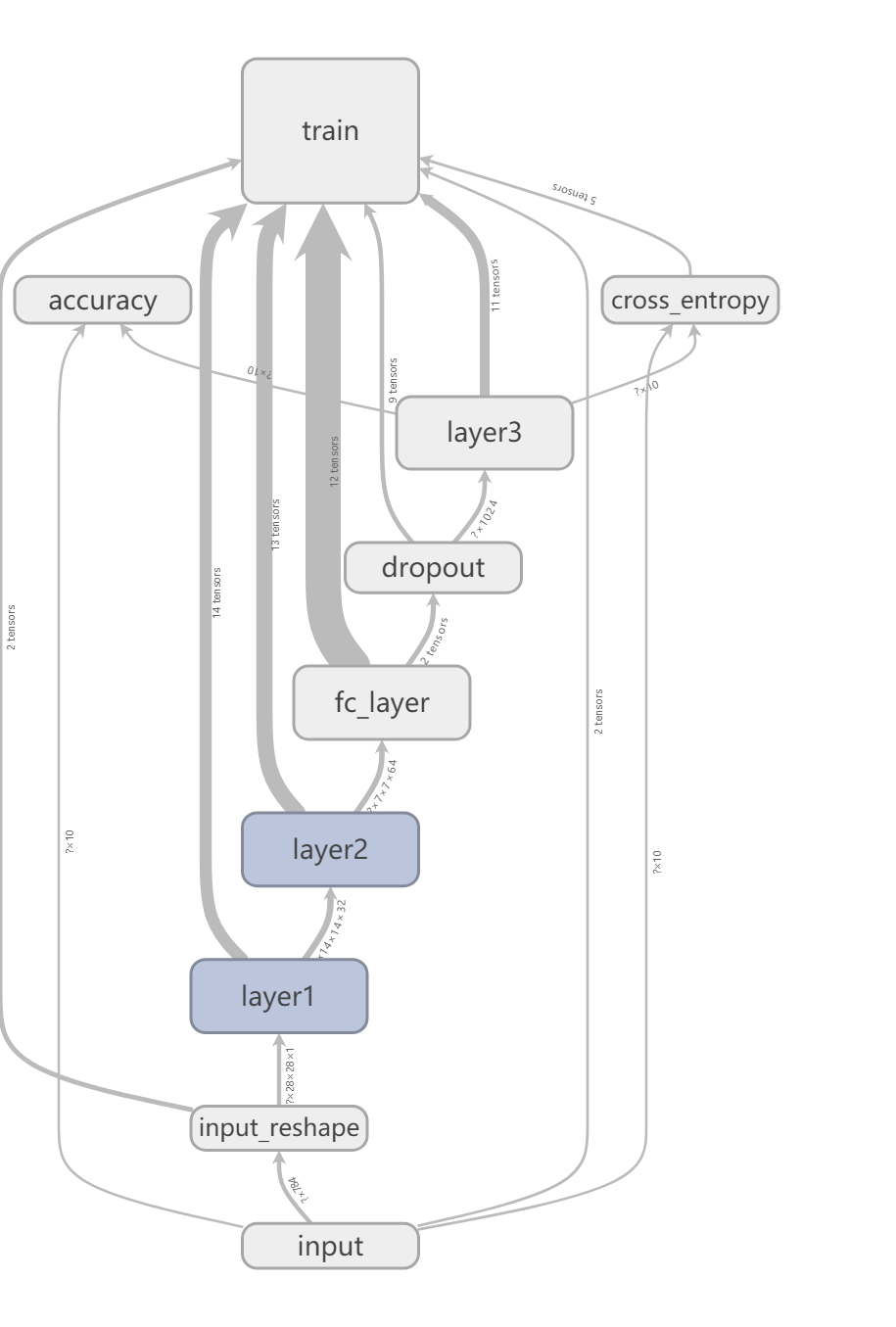
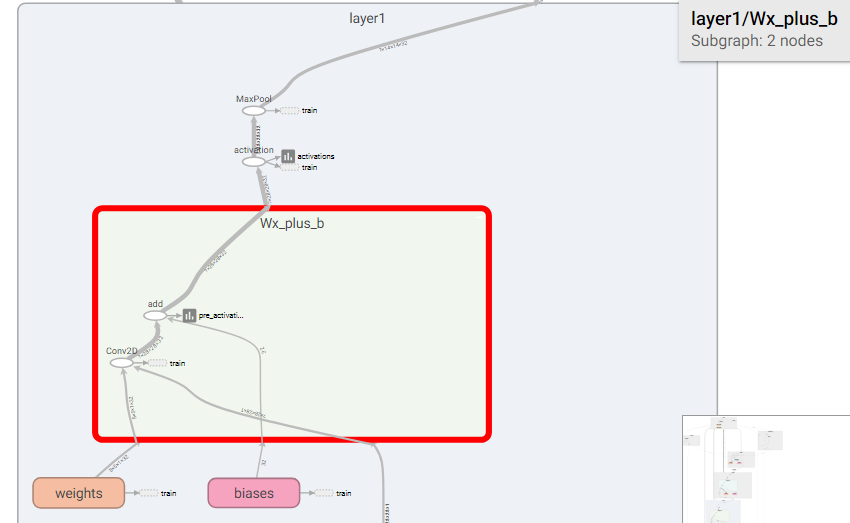
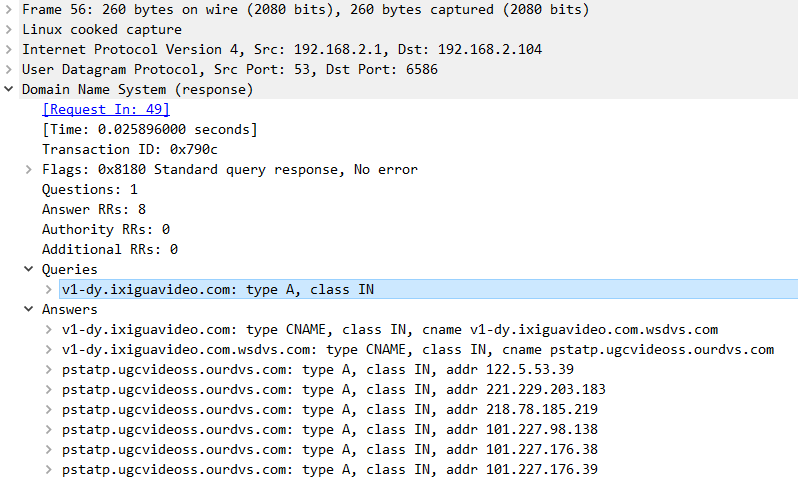
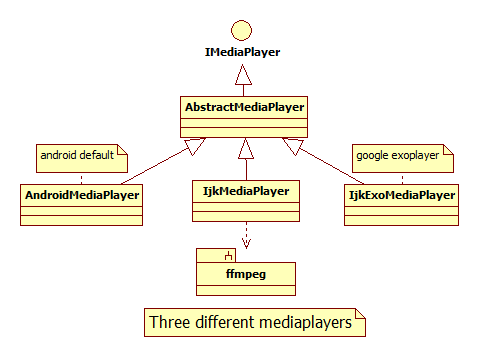
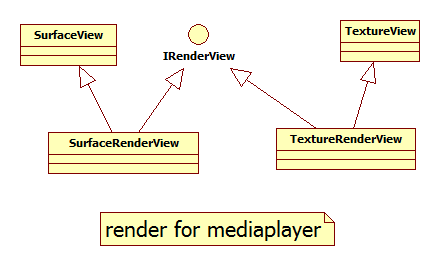
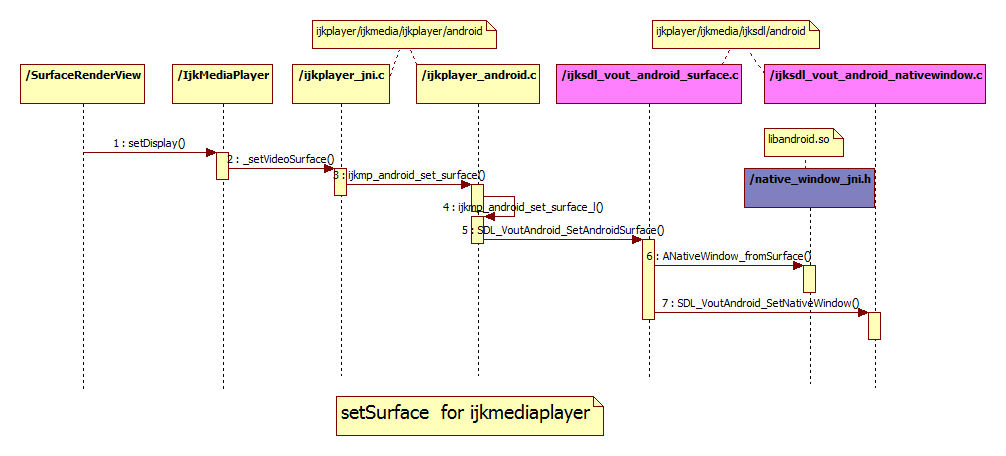
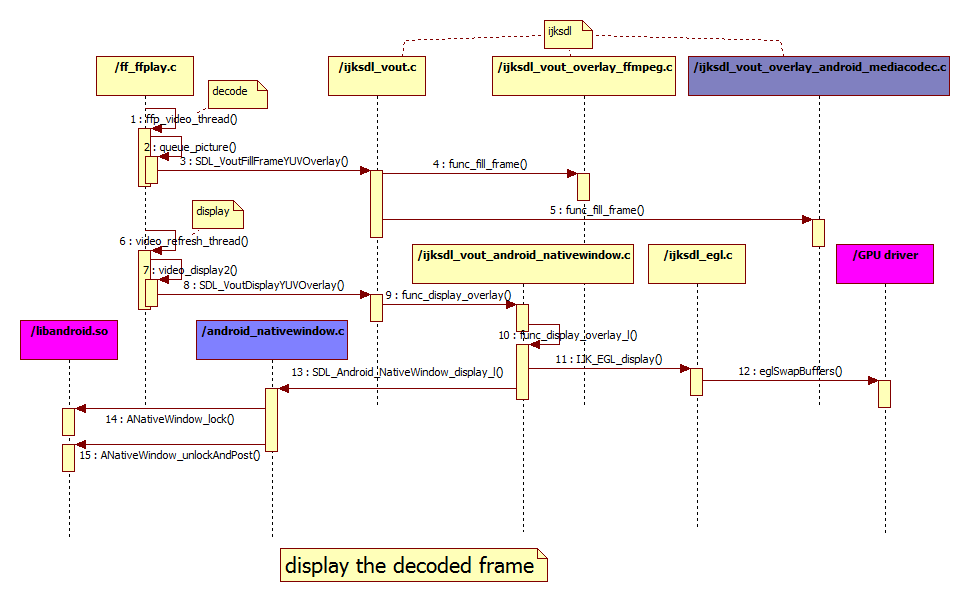
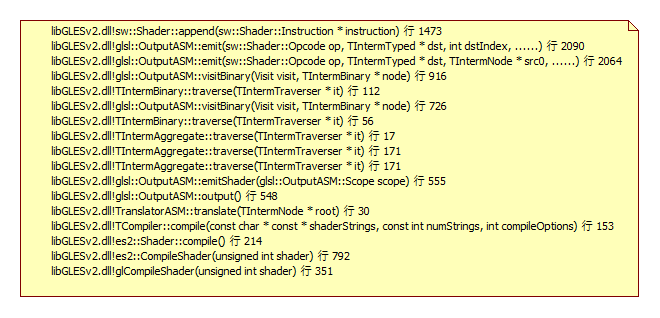
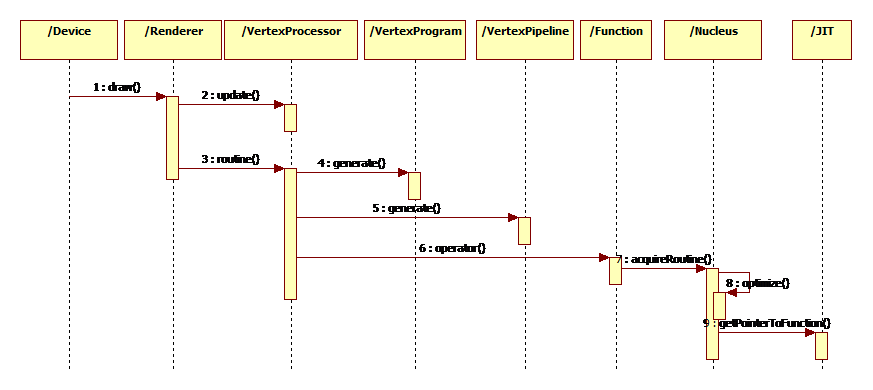
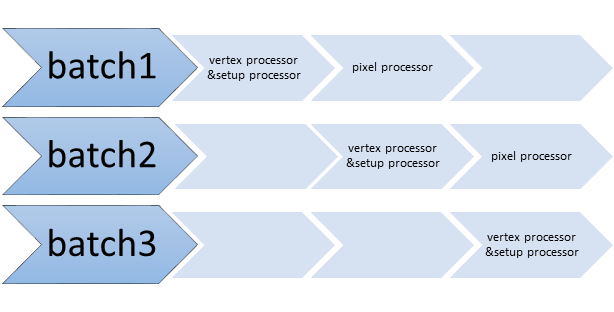
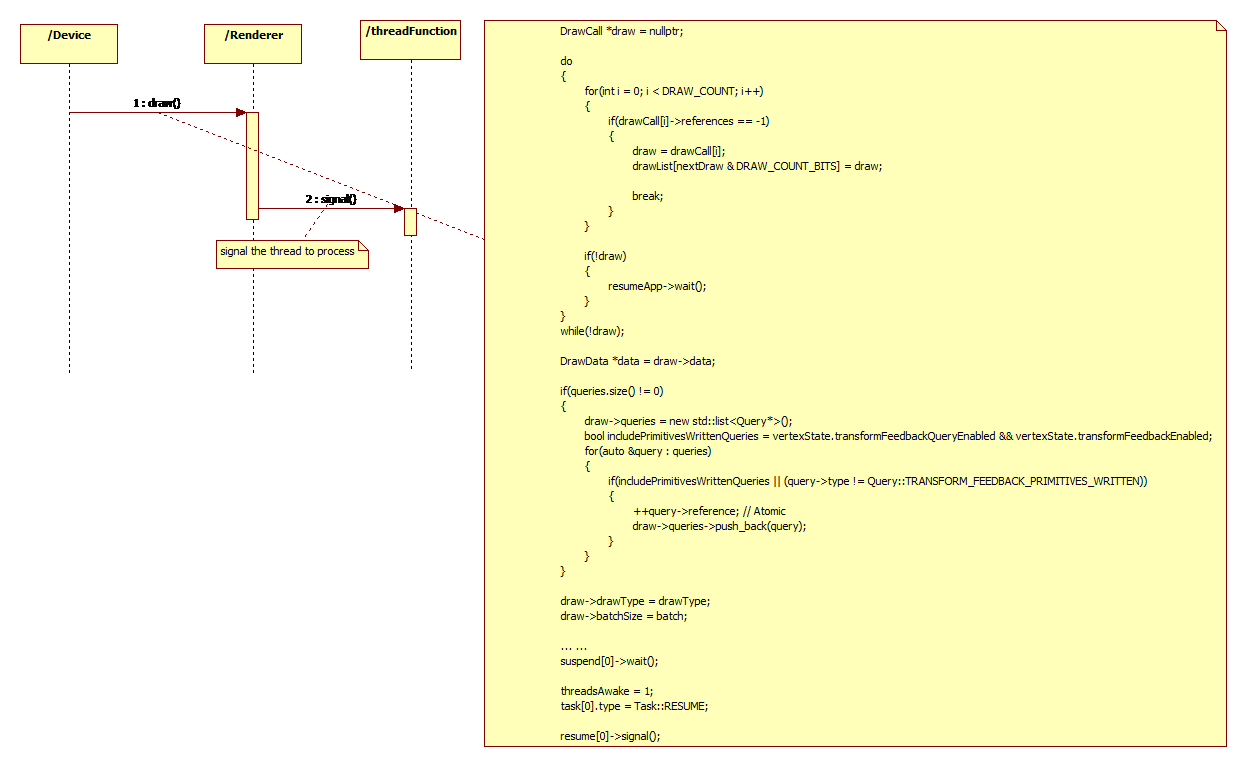
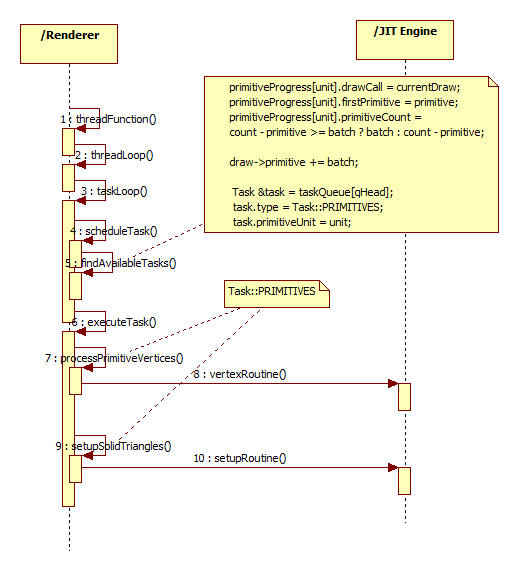
Here I list some callstack of tensorflow which is collected through gdb.
0x1 Session::Run()
|
|
0x2 OpKernel::Compute()
|
|
0x3 Producer of tenforflow
It is trigged by test.py to send command to tenforflow native code.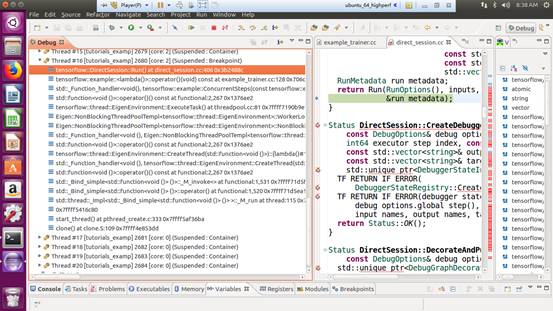
0x4 Consumer of tenforflow
Tensorflow’s thread pull task from the queue then execute it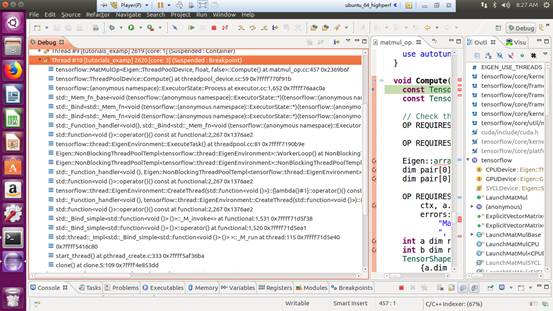
0x5 gdb debug of convolutional_network.py
|
|
|
|
|
|
|
|