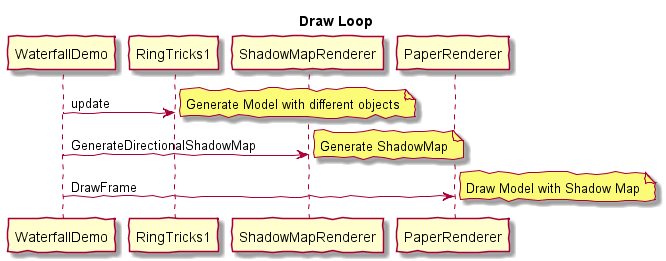
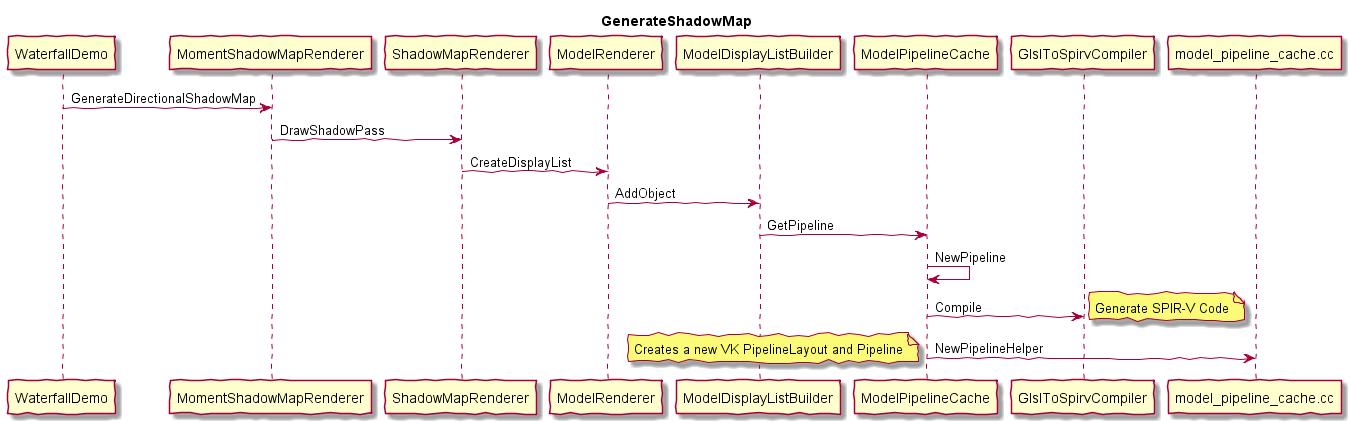
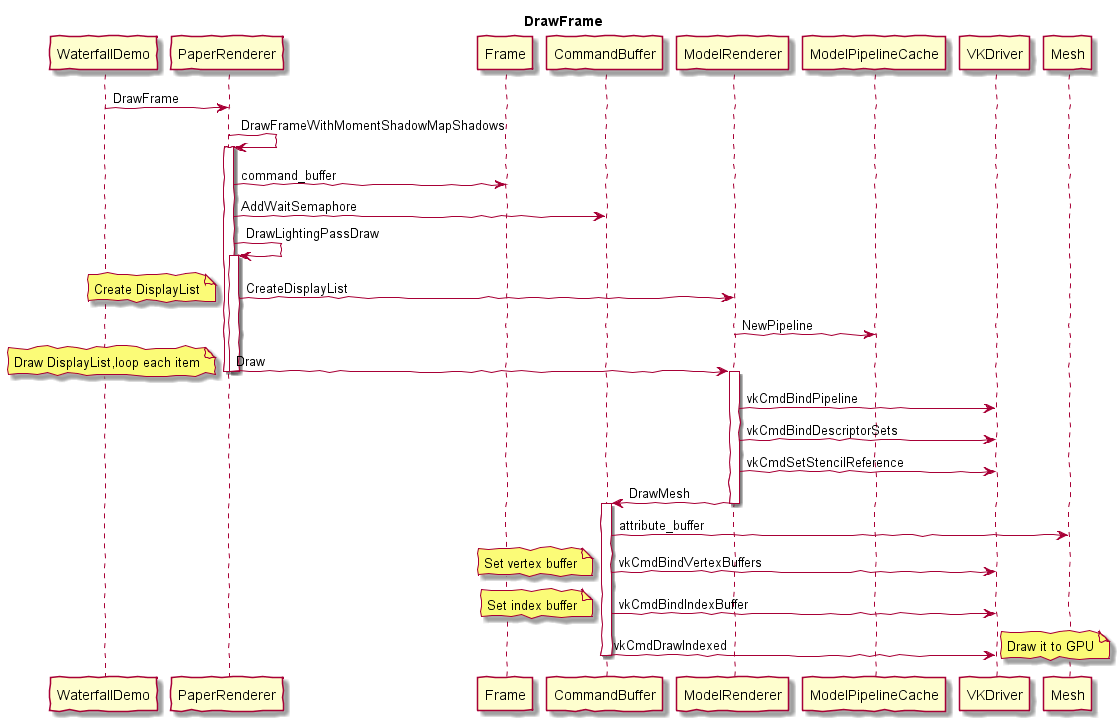
0x1 物理渲染和光栅化渲染
0x21 传统光栅化渲染器的特点
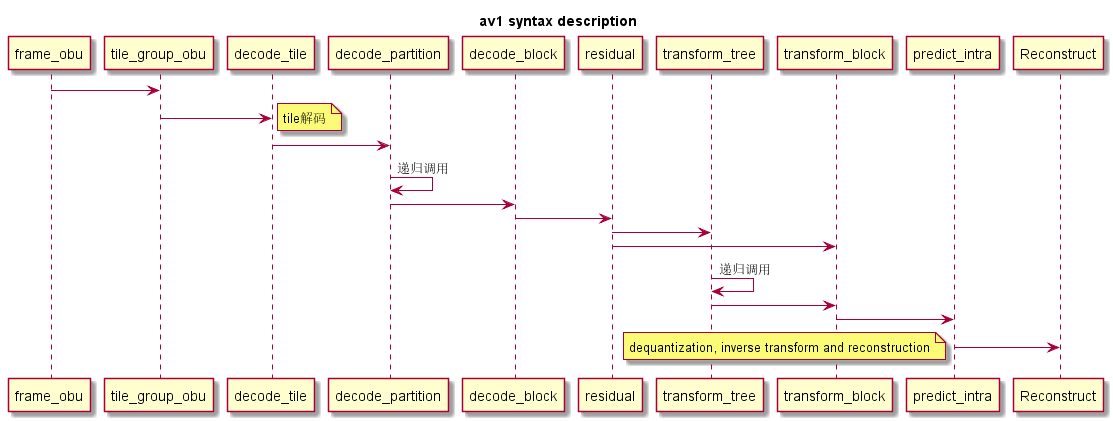
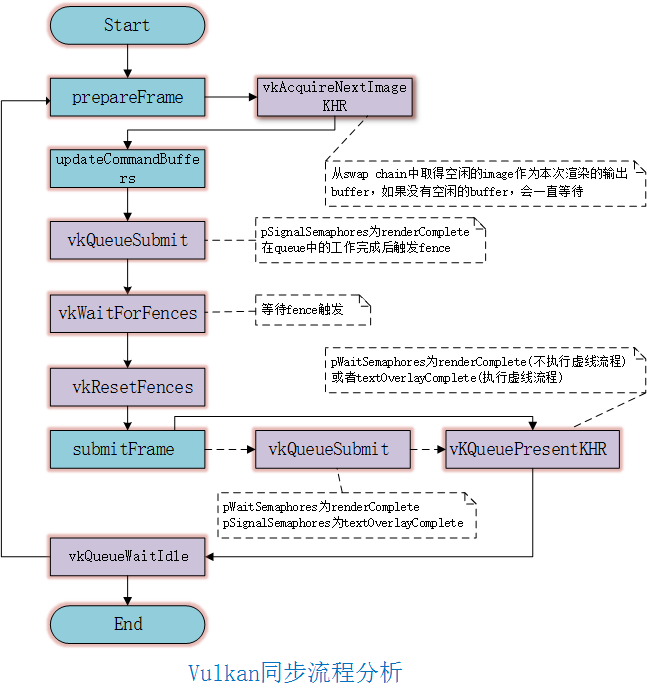
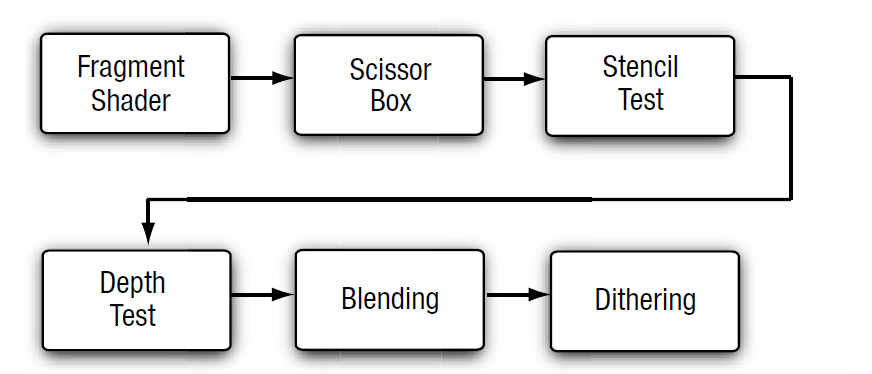
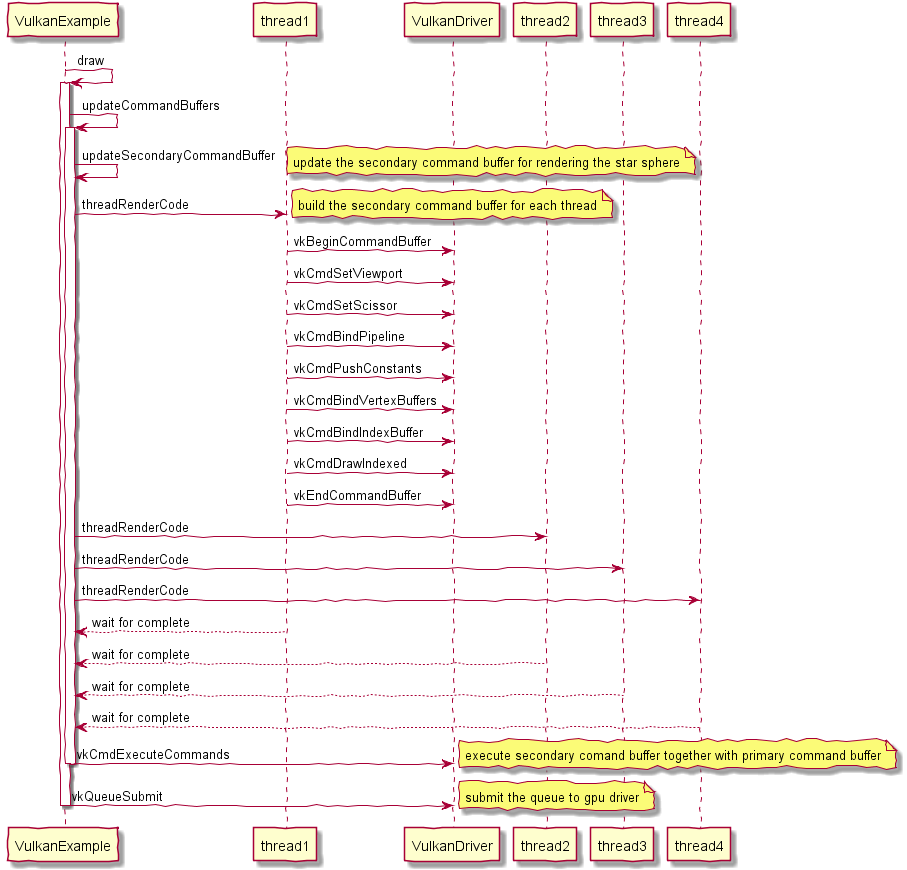
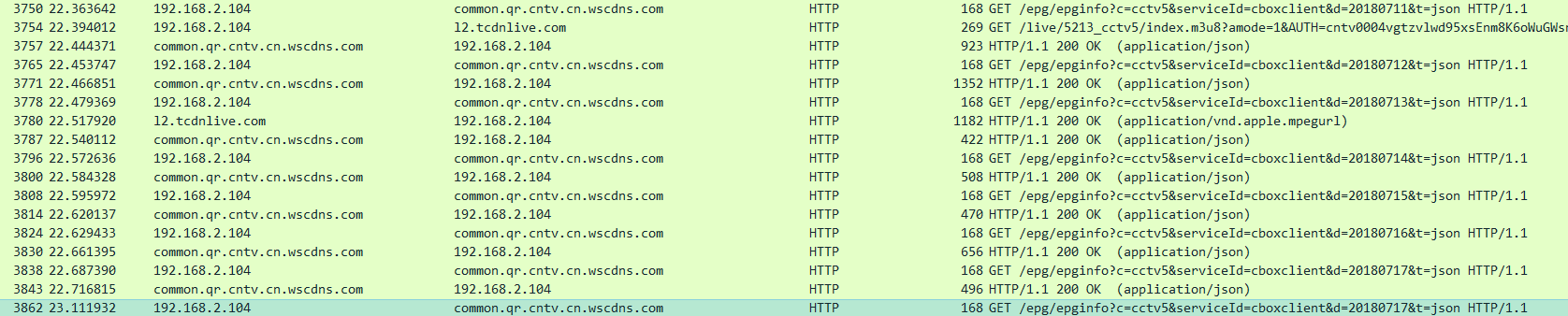
光栅化是指把3D空间的几何图形及其色彩信息转换至2D计算机屏幕上像素的过程。光栅化渲染器的pipeline包括Vertex Shader,Rasterization,Fragment Shader等阶段,目前GPU硬件也是采用这种高效率的光栅化架构。基于这些GPU硬件设计的渲染API有Windows上的DirectX,跨平台的OpenGL和Vulkan,已经Apple的Metal等。应用程序可以基于这些渲染API开发出酷炫的3D效果。但是这种光栅化的缺点也很明显,那就是无法完全模拟真实场景下的光线传播,导致绘制效果失真。
下图说明了光栅化渲染器的流水线。
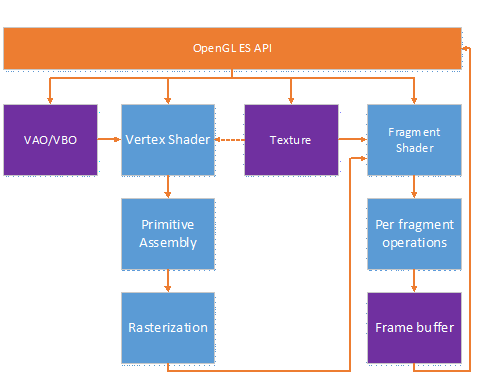
现代GPU中vertex shader和fragment shader一般是逻辑的概念,当时比较早的GPU是采用两种独立的硬件单元(不是Unified Shader)来实现的,如ARM Mali-400就是这种架构,这种架构的缺点是vertex shader和fragment shader的负载没办法平衡,极端情况下会出现其中一种硬件Shader满负荷运行,另外一种硬件Shader空闲的情况。后来的架构一般是基于通用可编程计算单元实现这些功能。也就是我们常说的Unified Shader架构。如树莓派中的Soc VideoCore采用了BroadCom V3D GPU, 其中的Unified Shader中采用QPU这种通用可编程计算单元来实现。
移动GPU相对桌面GPU的架构也有差别,因为移动平台上对带宽及功耗的要求都比较高。
桌面GPU一般采用IMR(Immediate Mode Rendering)架构, 这种架构需要同时对该次渲染的全部物体进行处理,需要频繁访问系统帧缓存(位于系统内存里),故对带宽要求较高。
移动GPU一般采用TBR架构(Tile Based Rendering)。TBR架构包括两个阶段Tiling和Binning。Tiling阶段把整个画面分成小块,然后计算每个小块中有哪些三角形需要处理。Binning阶段每次只对一个小块中包括的三角形进行处理,这种方式避免了对帧缓存(位于系统内存里)的频繁读写和修改,因为这些小块中的三角形的渲染是在GPU上的高速缓存里进行,所以能节约带宽,同时也减少了功耗。
Imagination在TBR架构的基础上又提出了TBDR(Tile Based Deferred Rendering), 在执行shading之前加入HSR(Hidded Surface Remove), 这个模块利用vertex shader/rasterization之后的fragment的深度值来优化掉不必要的计算。
0x22 物理渲染器的特点
物理渲染器PBR(Physically Based Rendering),也称光线跟踪器(Ray tracer)。采用该算法渲染的结果看起来更真实,因为它基于物理参数的方法来编写材质,而且考虑了光线的发射和折射,材质对光线的吸收等。
光线跟踪算法描述如下,沿着到达视点的光线的反方向跟踪,经过屏幕上每一个象素,找出与视线相交的物体表面点,并继续跟踪,找出影响点光强的所有光源,从而算出点上精确的光线强度。这种算法计算量极大,一般用于离线渲染。
一个典型的物理渲染器包括如下模块。
相机
光线-对象相交测试
光照分布/光线传播
递归光线跟踪机制
考虑到PBR的计算量太大,只适合离线渲染,后来基于全局光照Global Illuslaton技术的来实现实时PBR,因为考虑到了速度的提升,在渲染质量上会有损失。
早期Ray tracing的硬件有德国萨尔兰大学计算机图形小组在2005年的SIGGRAPH上展示了第一个实时光线追踪加速硬件——RPU(Ray Processing Unit),最近有NVIDIA在GPU硬件中加入了Ray tracing。
下图是采用Blender中的cycles物理渲染器渲染的坦克效果图,如果完全用CPU来计算,速度很慢,大概需要几十分钟。
0x2 Escher是如何做到物理渲染的?
Escher是Google下一代操作系统Fuchsia上内置的基于物理的真实感渲染引擎,它和Scenic一起提供了Fuchsia上的合成及进一步特效处理功能。
Escher目前看来主要采用光照和阴影技术来达到物理渲染的效果。
阴影是真实感渲染的一个重要组成部分,它对增加渲染物体的表面细节,帮助观察者增加对场景的空间感,从而更好地来判断物体的位置关系以及形状等有很大的帮助。可以说没有了阴影,3D场景中的真实感和吸引力将降低。
Escher中包括了如下几种阴影技术,ShadowMap、ShadowVolume等。
从Escher的实现代码可知,Escher还只是实现了部分物理渲染的功能,主要是通过light和shadow来体现真实感效果,后续要支持AR/VR中更多酷炫效果的话,需要进一步开发。
0x03 展望
随着GPU硬件中增加了Ray tracing的功能,主流API都增加了对Ray tracing的支持,未来Escher中可能会直接调用这些API(目前Escher中是调用了Vulkan,也就是说会调用Vulkan的Ray tracing支持)来加速Ray tracing的处理。
下来介绍一种主流API对 ray tracing的支持
0x31 Directx raytracing
DirectX Raytracing在DirectX 12 API的基础上引入了下面这些概念
DirectX Raytracing
What is DirectX Raytracing?
At the highest level, DirectX Raytracing (DXR) introduces four, new concepts to the DirectX 12 API:
The acceleration structure is an object that represents a full 3D environment in a format optimal for traversal by the GPU. Represented as a two-level hierarchy, the structure affords both optimized ray traversal by the GPU, as well as efficient modification by the application for dynamic objects.
A new command list method, DispatchRays, which is the starting point for tracing rays into the scene. This is how the game actually submits DXR workloads to the GPU.
A set of new HLSL shader types including ray-generation, closest-hit, any-hit, and miss shaders. These specify what the DXR workload actually does computationally. When DispatchRays is called, the ray-generation shader runs. Using the new TraceRay intrinsic function in HLSL, the ray generation shader causes rays to be traced into the scene. Depending on where the ray goes in the scene, one of several hit or miss shaders may be invoked at the point of intersection. This allows a game to assign each object its own set of shaders and textures, resulting in a unique material.
The raytracing pipeline state, a companion in spirit to today’s Graphics and Compute pipeline state objects, encapsulates the raytracing shaders and other state relevant to raytracing workloads.
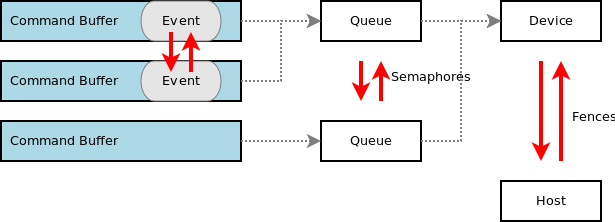
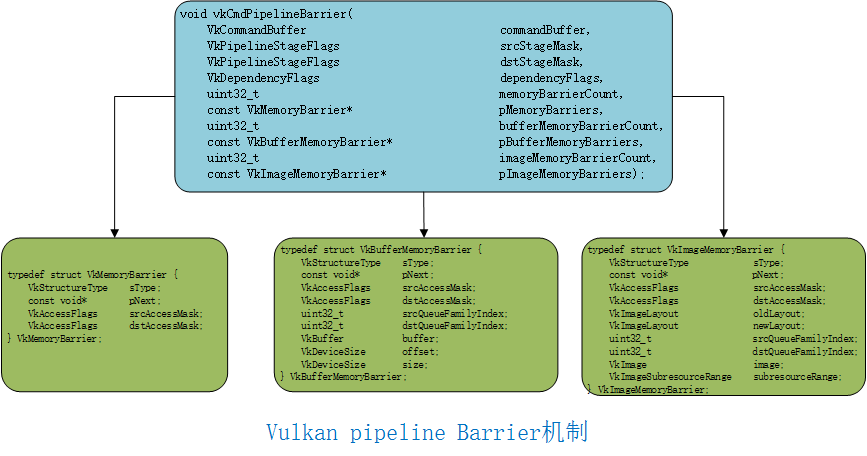
0x32 Vulkan ray tracing
NVIDIA提供了Vulkan的扩展了支持ray tracing。
Vulkan ray tracing
0x33 Metal ray tracing
Metal提供了ray tracing的支持。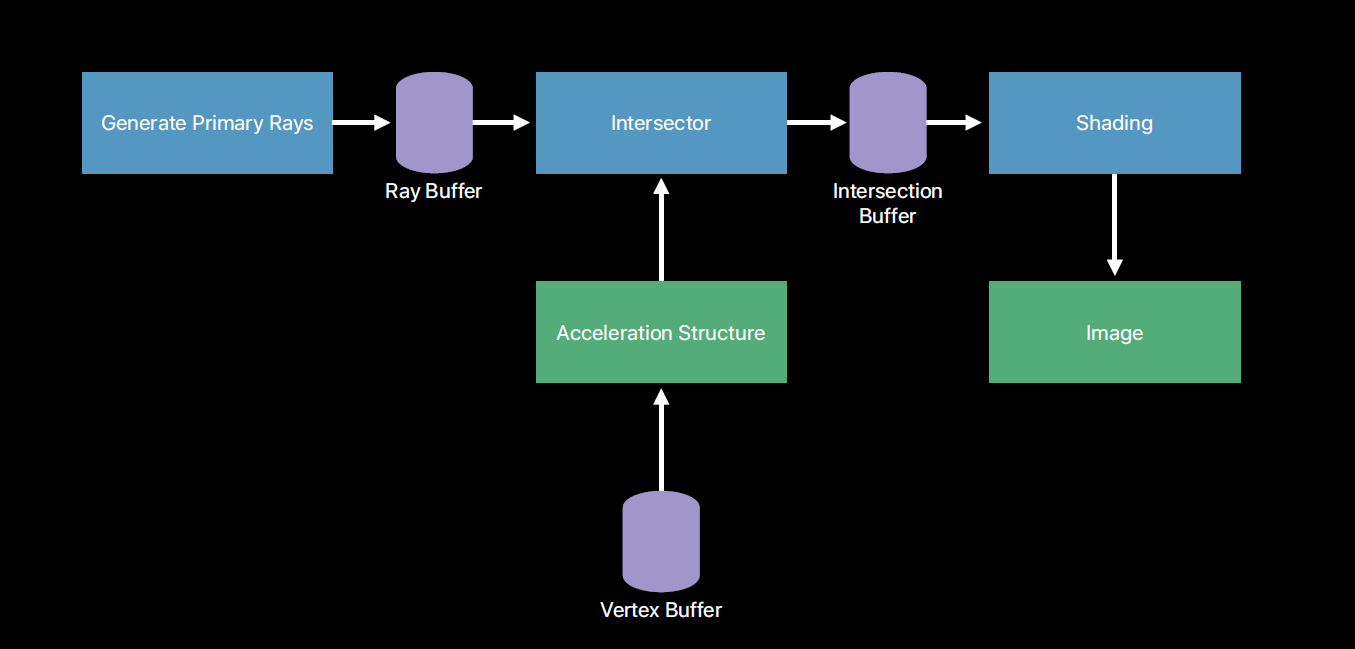
详细信息请参考
Metal ray tracing