0x1 硬件模块
分析Mali kernel driver代码,我们可以知道Mali Midgard硬件中包括下图所示的这些模块。下面简单介绍一下这些模块。
Shader Core指的是执行Shader的ALU单元,是可编程的运算单元。
Fixed Function Operator指的是Graphics Pipeline中诸如插值,光栅化等不可编程的硬件模块。
MMU是GPU中执行虚拟地址到物理地址转换的硬件模块。
Tiler指的是Tile Based Render中执行Tile划分的硬件模块。
Power Manager指管理GPU中各个硬件子模块的Power的硬件模块。
Job Executor,GPU User space driver根据应用执行的Graphics API来生成的Job,Job Executor是消费这些Job来驱动GPU硬件执行的状态机。
Cache,和CPU中的Cache类似,GPU中的cache也是为了提高GPU访问内存的速度与效率。
0x2 Power Manager
Mali Midgard中的Power Manager模块和SOC中的Power Manager模块关系如下图所示。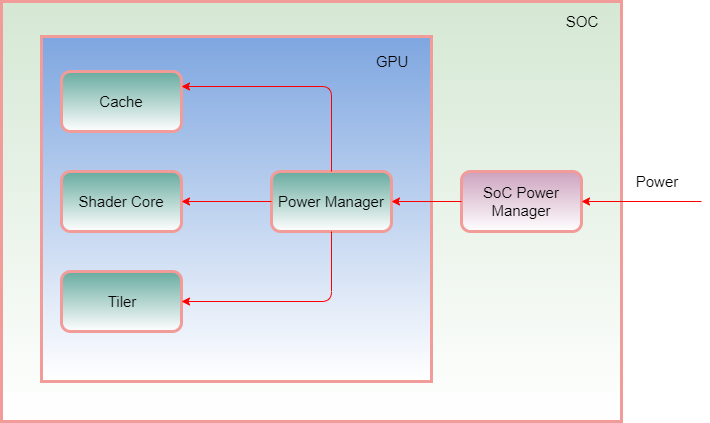
SoC中的Power Manager提供GPU硬件的Power输入。在SoC bring up阶段,经常会出现GPU不能工作的情况,这个时候需要和硬件工程师配合,检查SoC的Power输出到GPU的Power输入有没有配置好,是否没有上电,电压是否符合要求。另外经常出现的功耗问题也和GPU的Power设置相关,如suspend以后没有关闭GPU的Power,这样测量出来的功耗数据会很高。
如上图所示,GPU中包括三个可以独立控制Power的模块。分别是L2 cache,Shader cores和Tiler cores。
我们来想一下为什么要分成几个独立的Power模块呢?原因也是为了功耗的考虑。我们可以单独打开/关闭Shader cores的Power,同理对L2 cache和Tiler cores模块也是如此,这样可以根据GPU执行任务的情况灵活地控制这些模块Power的打开或者关闭。
0x3 内存分配和释放
下图说明了kernel driver中分配内存的执行流程。
这个流程是由gpu user space driver驱动的,最后调用alloc_pages从Linux系统的内存管理模块分配出内存,分配的内存返回给user space driver以后,可以写入GPU执行过程中需要的数据,包括Job数据,顶点数据,纹理数据等,注意这些数据的写入是由CPU来完成的。当数据在user space driver都准备好了以后,就可以trigger kernel driver来执行GPU硬件工作,这个时候GPU硬件需要读取前面准备好的数据,这时需要借助GPU MMU来完成地址的转换工作,否则GPU没有办法完成数据的正确读取。

前面介绍了内存是如何分配的,下面解释一下分配好的内存在被gpu user space driver填充好需要的数据以后,又回到gpu kernel driver是如何执行的呢?下图说明了执行的流程。具体的gpu job相关处理会在后面的章节中介绍。

0x4 GPU MMU
前面已经提到GPU MMU用于支持GPU对非连续内存的访问。
GPU MMU的实现和CPU用来管理内存的MMU实现机制类似,也就是提供了虚拟地址到物理地址的转换。
如果GPU中没有MMU,则GPU需要访问的物理地址空间必须是连续的,这对系统的内存管理提出了很高的要求,如在Android系统中只能使用通过ion driver分配的cma buffer(当然也可以是系统启动时候预留出来的物理连续内存, 不过这种情况不常见)。处理不好的话,很大概率会出现内存不足OOM(Out of memory)的错误。
驱动中提供了两种mmu的实现,根据硬件平台进行选择。
每一种mmu的实现都实现了下面的结构体。
GPU MMU中的页表结构和CPU MMU的类似,也是采用了多级页表结构。
GPU MMU中page fault的处理。
在MMU中断处理函数中判断是否发生了page fault,如果是则需要分配新的page给GPU,并把新分配的page信息更新到MMU中。
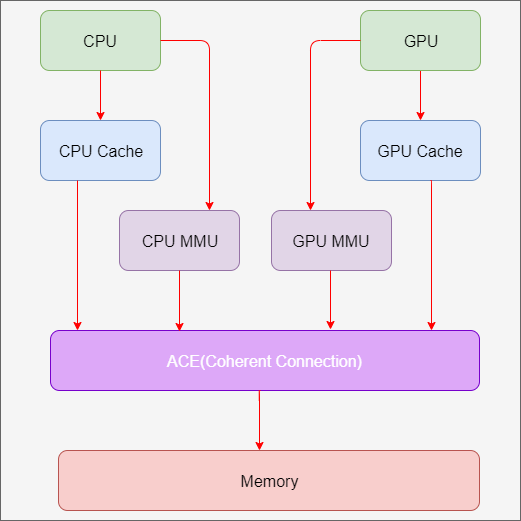
0x5 GPU Cache
GPU Cache位于gpu和memory之间,用来提高内存访问速度和效率。
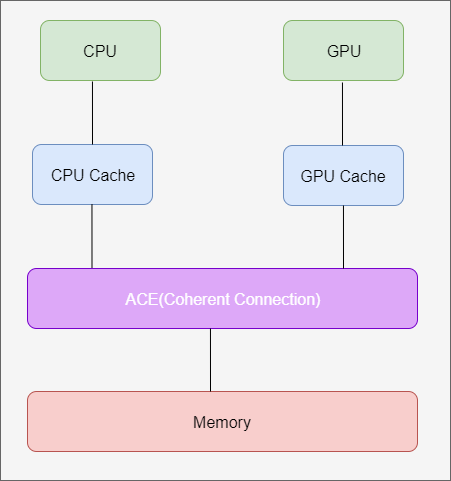
这里面涉及到CPU和GPU之间的cache coherency的概念,指的是硬件平台上CPU的cache和GPU的cache是否可以同步。
如上图所示,CPU需要对内存中地址为addr的内存进行写操作,如果CPU采用的是write through的cache机制,CPU对内存地址addr的修改会立即写入到内存中,如果在GPU的cache中原来保存有地址addr的cache,这个时候通过Coherent Connection机制来通知GPU,告知内存地址addr对应的cache失效了,下次GPU访问内存地址addr的内存,从GPU的cache中不能读取到内存地址addr对应的数据了(cache不命中),需要重新从内存中读取才能得到正确数据。
如果CPU采用的是write back的cache机制,CPU对地址addr修改以后不会立刻写回内存,这个时候可能大家觉得这样就没有办法通过到GPU了,其实还是有机制在这种情况下也是有办法来通过GPU去使对应的GPU cache失效的。这种机制叫“窥探(snooping)”协议,窥探协议的思想是,cache不仅仅在做内存传输的时候才和总线打交道,而是不停地在窥探总线上发生的数据交换,跟踪其他缓存在做什么。所以当CPU的cache代表CPU去读写内存时,GPU也会得到通知,这样CPU和GPU的缓存可以时刻保持同步。只要GPU或者CPU其中任何一方写了内存或者cache,对方马上就知道这块内存在它们自己的cache中对应的段已经失效,然后读取的时候需要从内存中读取。
注意在支持cache coherency的硬件平台上,上述操作是不需要软件干涉的,都是通过硬件来保证的。指ARM平台上CPU和GPU是cache coherency的。
但是如果CPU是x86的,GPU的mali的SoC平台中,要做到硬件的cache coherency比较困难,这个时候是需要软件来保证的。这样gpu driver的复杂度就增加了。
在mali 驱动中有下面三种cache coherency的设置。
在驱动初始化函数kbase_device_coherency_init()中会设置cache coherency的类型。
如下所示,默认是设置成COHERENCY_NONE
也可以通过dts来配置
如下代码中,在CPU更新完page directory以后,如果不是cache coherency平台,这个时候需要sync来保证cache的一致性。
注意这个时候page directoy是在CPU侧写入的,CPU写入有可能只是写到cache的write buffer中,并没有真正写入内存,需要通过dma_sync_single_for_device来保证cache的write buffer中的内容都
写入了memory,这样后续GPU访问page directoy的时候能取得正确的数据。
这里有一个疑问,就是如果GPU的cache中已经有了对应内存地址的缓存内容,在不是cache coherency的平台中,是如何通知到GPU,使其对应的cache失效的呢?这部分我的理解可能也是通过硬件总线来完成的。
|
|
如下代码所示,在security模式下关闭cache coherent,保证内存数据读写的安全性。
我们可以从下面的代码来理解一下dma_sync_single_for_cpu和dma_sync_single_for_device的区别。
kbase_sync_single_for_cpu等同于dma_sync_single_for_cpu。用于数据从GPU到内存的DMA传送刚刚完成的情况。当DMA传输完成时,GPU已经将数据传输到内存,但是cache中可能还有老数据,为了避免CPU读取还是cache中的老数据,需要调用dma_sync_single_for_cpu,在ARM平台上相当于”invalidate”操作,也就是使cache无效的操作。从上面的代码可以,DMA传输完成后,先是调用了dma_sync_single_for_cpu,CPU再从内存地址page_1中读取数据。
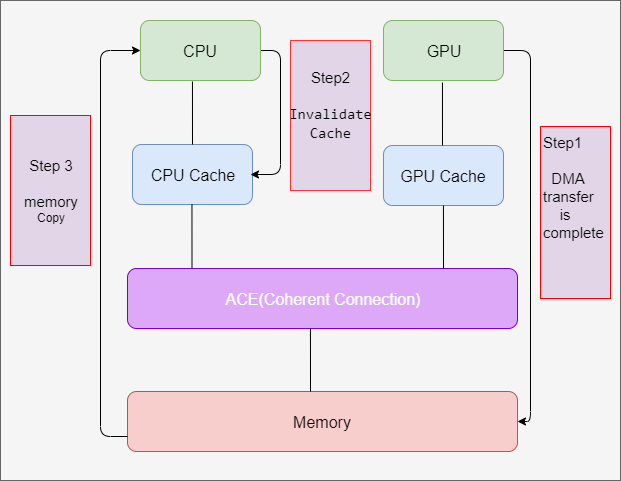
kbase_sync_single_for_device等同于dma_sync_single_for_device。用于数据从内存到GPU的DMA传送开始之前的情况,在CPU往内存的DMA缓冲区写入数据之后,这个时候数据可能没有立即反映到内存的DMA缓冲区上,因为该DMA缓冲区可能带有write buffer,导致数据只是写到了write buffer中,没有写入内存的DMA缓冲区上(为什么没有立即写入到内存的DMA缓冲区上呢? 是为了等write buffer达到一定的大小以后一次写入到内存,为了提高效率)。这个时候需要调用dma_sync_single_for_device来做flush/clean操作,这样后续GPU启动DMA传输的时候可以从DMA缓冲区得到正确的数据。
如上代码所示,dma_sync_single_for_device之前调用了memcpy把数据传输到DMA缓冲区中,然后执行dma_sync_single_for_device()flush
write buffer中的数据,保证后续GPU的操作能得到正确的DMA数据。

0x6 中断处理
从下面代码中我们可以知道gpu kernel driver需要处理下面三种中断。
下图是三种中断处理函数的执行流程。
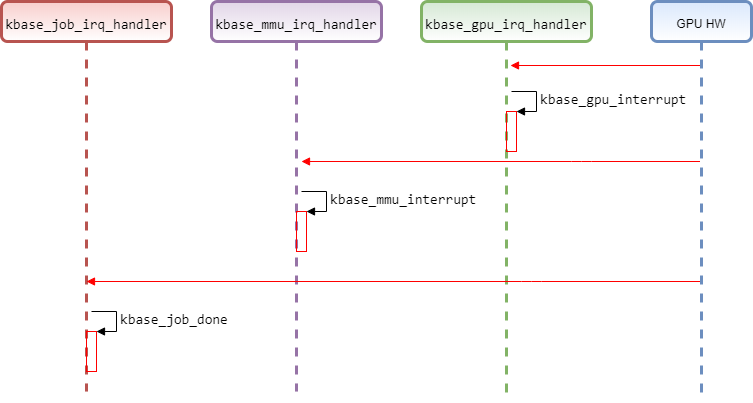
中断的处理流程如下。
- 调用request_irq注册中断。
- 操作GPU register启动中断。
- GPU硬件执行完成,触发中断。
- 处理中断处理函数,读取GPU register来判断硬件执行情况做进一步动作。
0x7. GPU Job处理
Mali GPU Job可以理解成GPU硬件能理解的IR(中间语言)。在Broadcom V3D中的CLE(control list executor)也是类似的概念。
gpu user space driver简单来说就是把上层应用的API调用转换成Job的描述。
kernel driver拿到这些Job以后,把Job的内存地址告诉GPU硬件,GPU硬件的Job Executor就开始parse这些Job,然后驱动GPU硬件的其他模块完成渲染或者计算工作。
Job可以组成Job chain的形式,Job chain中Job的执行可以有前后关系,如果该Job中需要读取texture信息,则Job中还包括texture存储位置的地址信息。
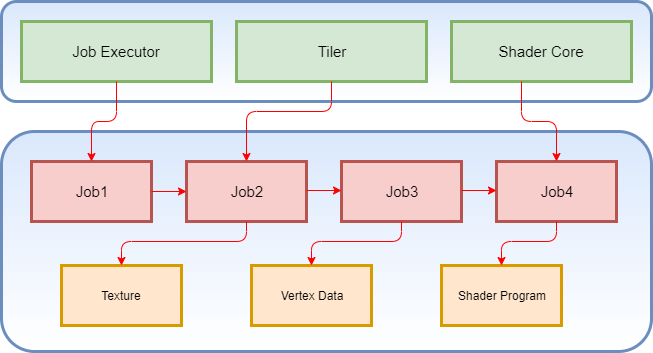
下面的流程说明了GPU Job在kernel driver中是如何提交给GPU硬件的Job Executor的。
0x8. GPU DVFS
这部分是根据GPU的loading进行动态调整GPU的运行频率,也可以动态调整GPU Power的电压。这部分的实现依赖于Linux kernel提供的DVFS(Dynamic Voltage and Frequency Scaling)机制。
当然GPU dvfs的启用与否是根据场景来的。在功耗不敏感的场景下,如汽车娱乐系统中,GPU DVFS一般是关闭的。