0x1 Overview
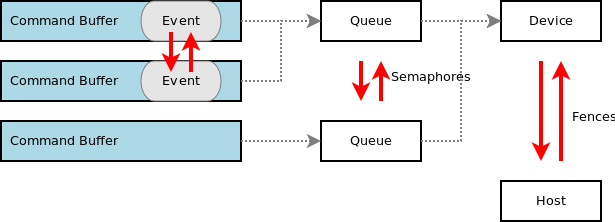
Vulkan的一大优势是能通过多线程来提升CPU bounding场景的performance,这依赖于其提供了下面几种同步机制。
Semaphores,用于多个queue之间的同步或者是一个queue的任务提交同步。
Events,用于一个command buffer内部的同步或在同一个queue内部多个command buffer的同步。
Fences,用于提供devive和host之间的同步。
barriers,用于精确控制pipeline中各个pipeline阶段的资源流动。
下图说明了这几种同步机制适用的场景。
0x2 Details
0x21 Pipeline Barrier
Barrier是一种同步机制,用来管理内存访问和同步Vulkan pipeline中各个阶段里的资源状态变化。通过这种机制来fine-grained控制command buffer执行过程中资源在pipeline的各个阶段中的流动。
Vulkan通过API vkCmdPipelineBarrier()来控制三种barrier操作,Memory barrier, Buffer Memory barrier和Image Memory barrier。
其中Memory barrier, Buffer Memory barrier会控制资源在pipeline各个阶段的执行次序。其作用有两个,
一个作用是控制执行顺序,对写后读(WaR),读后写(RaW),写后写(WaW)三种情况提供保护。另外一个作用是保证pipeline不同部分中数据的视图的一致性,因为pipeline不同stage之间可能有cache,在插入了barrier的地方需要flush cache。
Image Memory barrier的作用是控制对图像的访问。
三种barrier的数据结构如下所示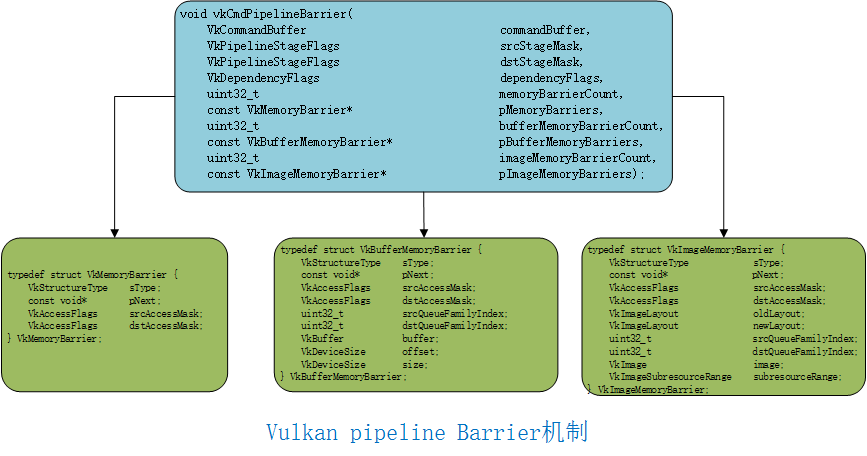
Vulkan的pipeline包括下面这几种,Command的执行从top开始,然后执行类似VS,FS之类的pipeline,最后是bottom。
|
|
但是如何设置vkCmdPipelineBarrier中source stage和dest stage呢?
最简单的方式是把source stage设置为VK_PIPELINE_STAGE_BOTTOM_OF_PIPE_BIT,dest stage设置为VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT。
这种设置会等待前面command buffer的所有pipeline都执行结束了,后面command buffer才能开始,很明显这种设置多个command buffer没有并行执行,command buffer之间只是串行的,performance应该会受到影响。
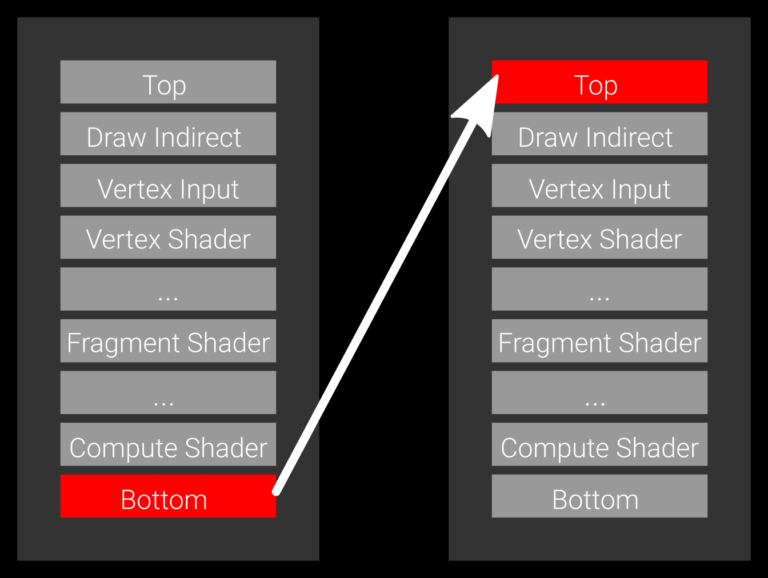
如果希望能在多个command buffer之间并行执行,需要根据实际情况设置source stage和dest stage。
假如vertex shader后面接了一个compute shader, compute shader执行的时候需要读取vertex shader的执行结果,
我们可以把source stage设置为VK_PIPELINE_STAGE_VERTEX_SHADER_BIT,dest stage设置为VK_PIPELINE_STAGE_COMPUTE_SHADER_BIT。
更详细的介绍,请参考后面的代码说明。
原则上source stage和dest stage的设置应该尽量使下图中的ubblocked pipeline(green stages)尽可能地多,这样并行度会越高。
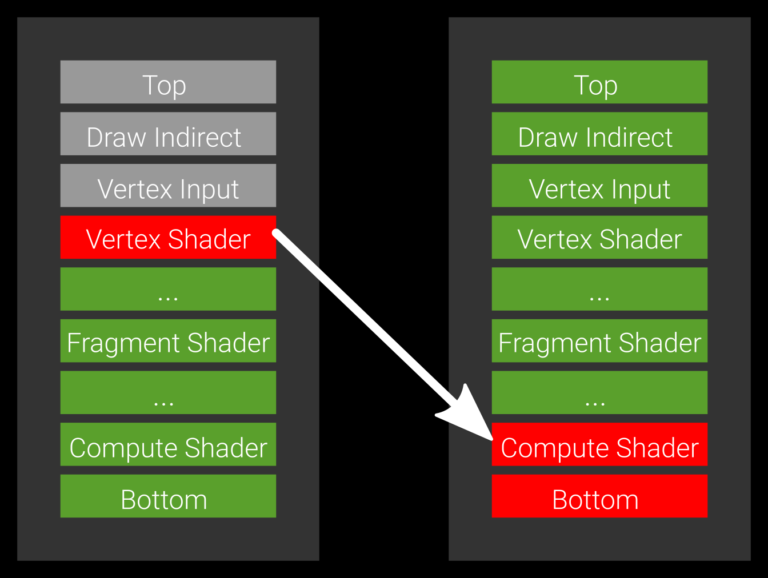
Memory barrier示例代码
根据需要,创建两个queue(graphics queue和compute queue)和对应的command buffer.
下面的代码说明了如何在这两个command buffer执行的过程中插入barrier, 从而实现资源访问的控制。
|
|
Image barrier示例代码如下
|
|
0x22 Semaphore/Event/Fence
下面说明并行渲染多帧时采用的同步机制。
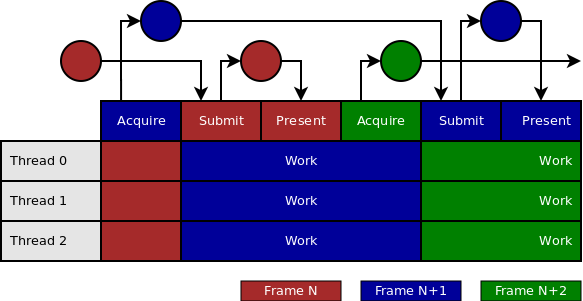
如上图所示,当swap chain中的image可用时,vkAcquireNextImageKHR会触发一个semaphore a,vkQueueSubmit拿到这个semaphore b以后开始执行command buffer的命令,执行command buffer的过程中会往vkAcquireNextImageKHR得到的image(这个image类似于frame buffer的概念)中写内容,执行完毕以后会触发semaphore b, vkQueuePresentKHR等待这个semaphore b触发以后就把image的内容绘制到display上。
当第N frame在Submit任务到GPU上执行的时候, (N+1)frame同时在CPU上开启多线程往多个command buffer中生成command,这样CPU和GPU相互配合,提升performance。
下面说明渲染一帧时内部采用的同步机制。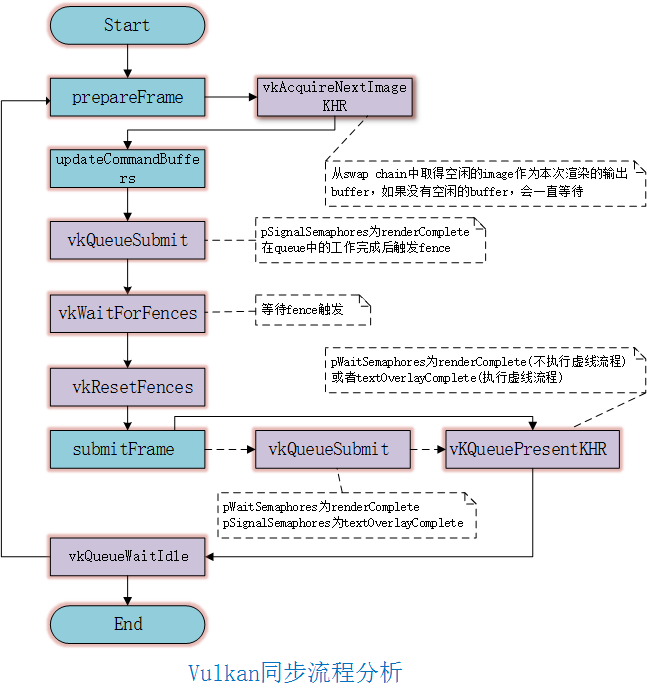
上图中第一个vkQueueSubmit的参数如下
然后执行vKQueuePresentKHR,这边的wait semaphore是前面一步的renderComplete, 表明只有renderComplete被触发以后vKQueuePresentKHR才能被执行。
上面虚线部分表明在执行vKQueuePresentKHR之间,还有一个text overlay command buffer需要执行。
这个command buffer的wait semaphore为renderComplete。
|
|