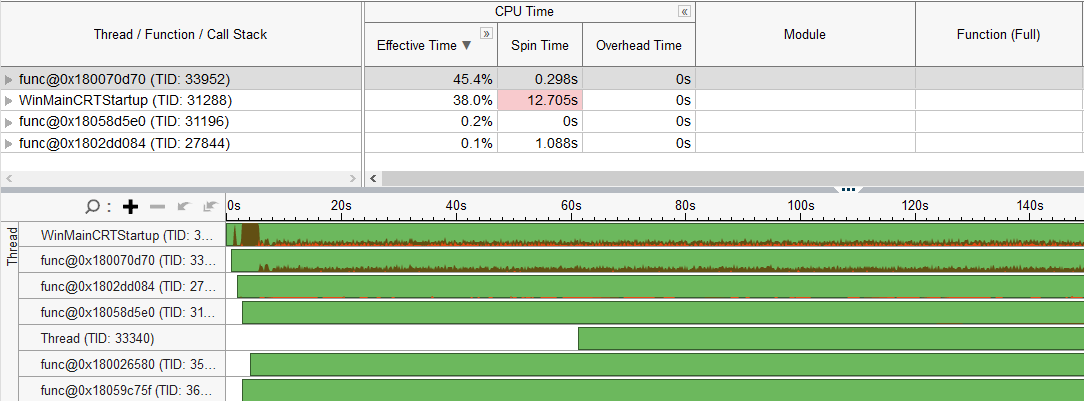
0x1 Vulkan mechansim for multithread cpu
Vulkan uses command buffer to record the gpu states, then execute the command buffer. on opengl, we have only one command buffer to record the gpu states, but on vulkan, we can have several command buffers to record gpu states in parallel.
If the draw task is cpu bounding, which means the loading is cpu heavy, and these tasks can be splitted into several threads to execute in parallel, then we can assign different command buffers to threads, and record the gpu states into these command buffers in parallel, after all threads are ready, we can submit these command buffers to gpu driver, then gpu driver executes it.
Here is the vulkan command buffer execution models.
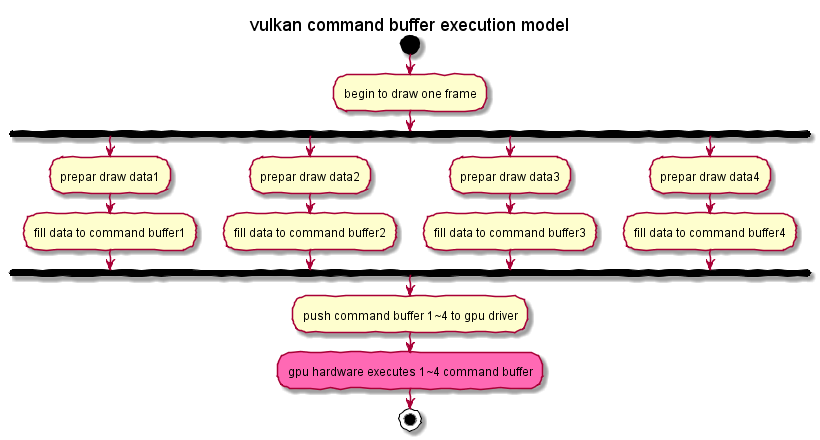
Is it possible for every graphics draw pipeline can be benefit from the multithread command buffer mechansim?
It is case by case.
If the drawing data preparing task on cpu can’t be splited into several parallel tasks, likes it has dependency each other(one draw has to be drawed before another one), it can’t be benefited from the mulithread command buffer mechansim.
Otherwise it can benefit from it.
0x2 Test case analysis
We use SaschaWillems’s Vulkan example as the test case to check how vulkan can be benefited from multithread.
This test generates command buffers in parallel using multithreaded mechansim. these generation command buffers are configured as the vulkan secondary command buffers, they are executed and submitted together with the primary buffer once all threads have finished.
Here is the sequence about how it works.
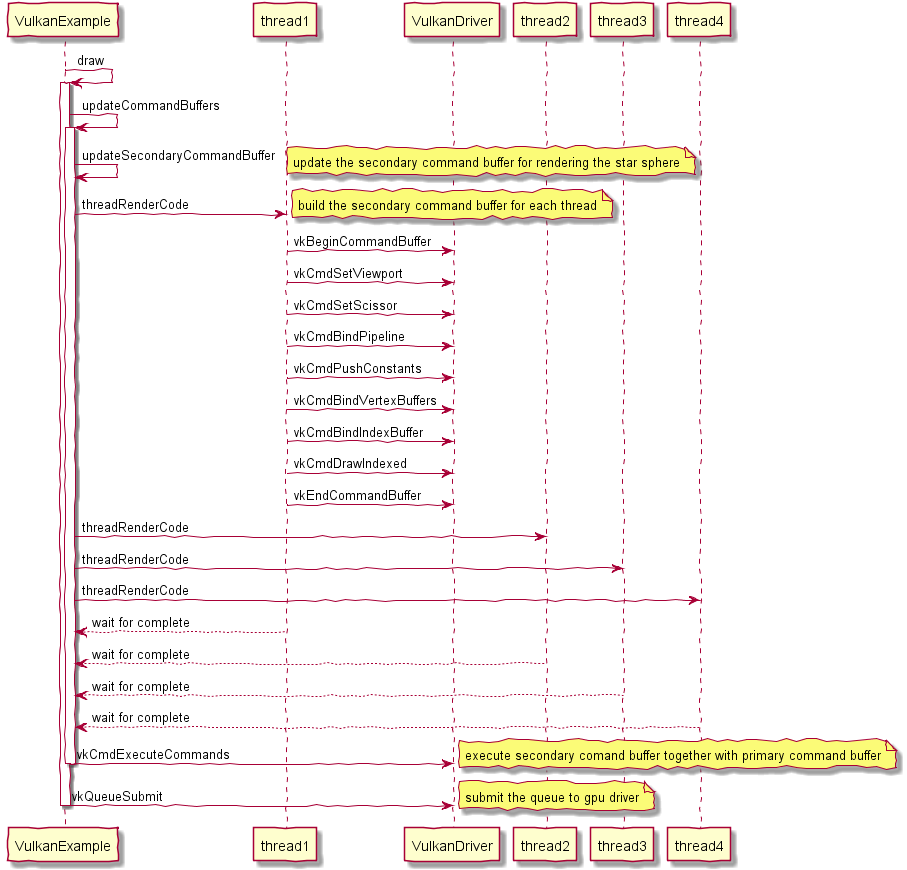
Let’s discuss the detail sequence of this test case.
0x21 Prepare
It prepares the vulkan initialization, load the mesh, create the multithread for command buffer execution.
|
|
Here is the code of VulkanExampleBase::prepare(), it does vulkan initialization.
createCommandPool() creates command buffer through vkCreateCommandPool().
setupSwapChain() creates the swapchain.
createCommandBuffers() creates one command buffer for each swap chain image and reuse for rendering.
setupDepthStencil() steups depth and stencil setting.
setupRenderPass() create render pass through vkCreateRenderPass().
createPipelineCache() create pipeline cache through vkCreatePipelineCache().
setupFrameBuffer() creates frame buffers for every swap chain image through vkCreateFramebuffer().
0x22 Command buffer generation
It creates primary/secondary command buffer through vkAllocateCommandBuffers.
It will create thread data for each thread, the thread’s number depends on its core’s number.
For each thread, it will create a command pool for it, then create one secondary command buffer, then create command buffers for each objects.
The buffer number for objcts is numObjectsPerThread, it is the number of animated objects to be rendered per thread, in this test case, the total animated objects is 512, so numObjectsPerThread is 512/numThreads, numThreads is core’s number.
Then it initializes push constants for each object.
|
|
0x23 Draw
Here is the code about drawing.
|
|
The main update function is updateCommandBuffers().
It uses a thread pool to generate drawing command in each thread, the thread function is threadRenderCode.
Firstly, it start to queue command to primary command buffer through vkBeginCommandBuffer().
The primary command buffer didn’t contain any rendering commands, the rendering command are stored (and retrieved) from the secondary command buffers.
Then it calls vkCmdBeginRenderPass() to start a new RenderPass.
|
|
Once the setup for primary command buffer is ready, it starts to config secondary command buffers.
The secondary command buffer is for star background sphere rendering.
|
|
Now we will see how command buffer generation through multithread.
Each object is executed in one thread.
After secondary command buffer is ready, it executes render commands from the secondary command buffer through vkCmdExecuteCommands()
|
|
0x24 Multithread comand buffer generation
Let’s see how the multithread function threadRenderCode work.
It builds the secondary command buffer for one object of each thread.
threadIndex is thread index.
cmdBufferIndex is the command buffer index.
It begin to push command buffer to gpu driver through vkBeginCommandBuffer().
Then it prepares the data for push constant.
And push the data to gpu driver through vkCmdPushConstants().
Then it pass vertex data and index data through vkCmdBindVertexBuffers() and vkCmdDrawIndexed().
Then it issues draw operation through vkCmdDrawIndexed().
Then it stops the recording of command buffer through vkEndCommandBuffer().
|
|
0x3 Performance analysis
Here we will compare the performance with/without multithread support using vulkan.
And then check the thread profiling data of them.
0x31 With multithread
Here is the performance of using vulkan with multithread support(4 threads), the fps is 28.

Here is the cpu profiling data of it, we can see the cpu loading is balanced to 5 threads, one is main thread, other 4 threads are working thread for generating object for vulkan command buffer, the working thread number 4 is the number of cpu cores.
0x32 Without multithread
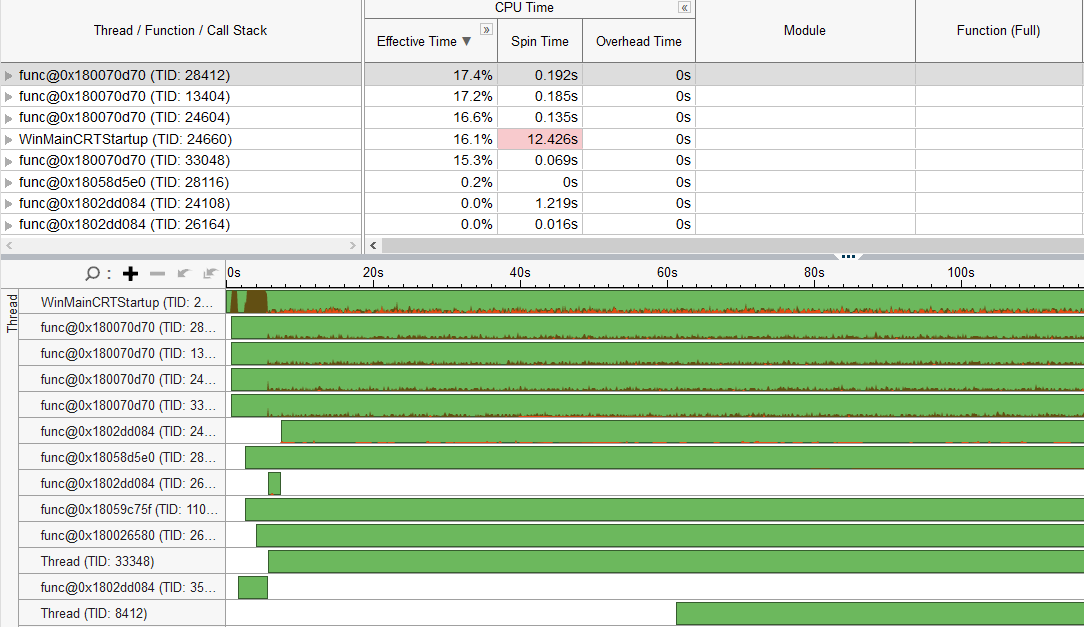
Here is the performance of using vulkan without multithread support(1 thread), the fps is 17.
We can see the fps gain from 1 thread to 4 threads is 65%(17 -> 28).

Here is the cpu profiling data of it, we can see the cpu loading is only bounded to two threads, one is the main thread, another is the working thread.