0x1 学习率简介
学习率是一个重要的超参数,在大多数神经网络优化算法(如SGD、Adam)中都会用到,它控制着我们基于损失梯度调整神经网络权值的速度。如果学习率过大,可能会错过最小值,并且可能造成不能收敛,损失在某一个值附近反复震荡。如果学习率过小,我们沿着损失梯度下降的速度就很慢,收敛的速度也很慢。
神经网络优化算法的功能是,控制方差,寻找最小值,更新模型参数,最终使模型收敛。
神经网络更新参数的公式为:θ=θ−η×∇(θ).J(θ),其中η是学习率,∇(θ).J(θ)是损失函数J(θ)的梯度。
学习率是神经网络中难以设置的超参数之一,它对模型的性能有很大的影响。目前出现了很多自适应学习率算法,如下文测试中用到的Adam。在下面的测试中发现,虽然Adam会在优化的过程中动态调整学习率,初始的学习率设置还是会对模型的准确率有很大影响。
0x2 构造计算图
用python编写tensorflow测试代码,构造如下图所示的卷积神经网络,用来对MNIST数据集进行0~9分类。
从下图神经网络图可知,首先载入MNIST数据,然后进行处理,包括卷积层layer1, 卷积层layer2, 接下来是一个全连接层fc_layer, 接下来是dropout层,最后连接上softmax层layer3, 得到概率输出。
优化算法采用Adam,在设置Adam优化器的时候设置需要初始学习率,其代码如下。
总体网络图如下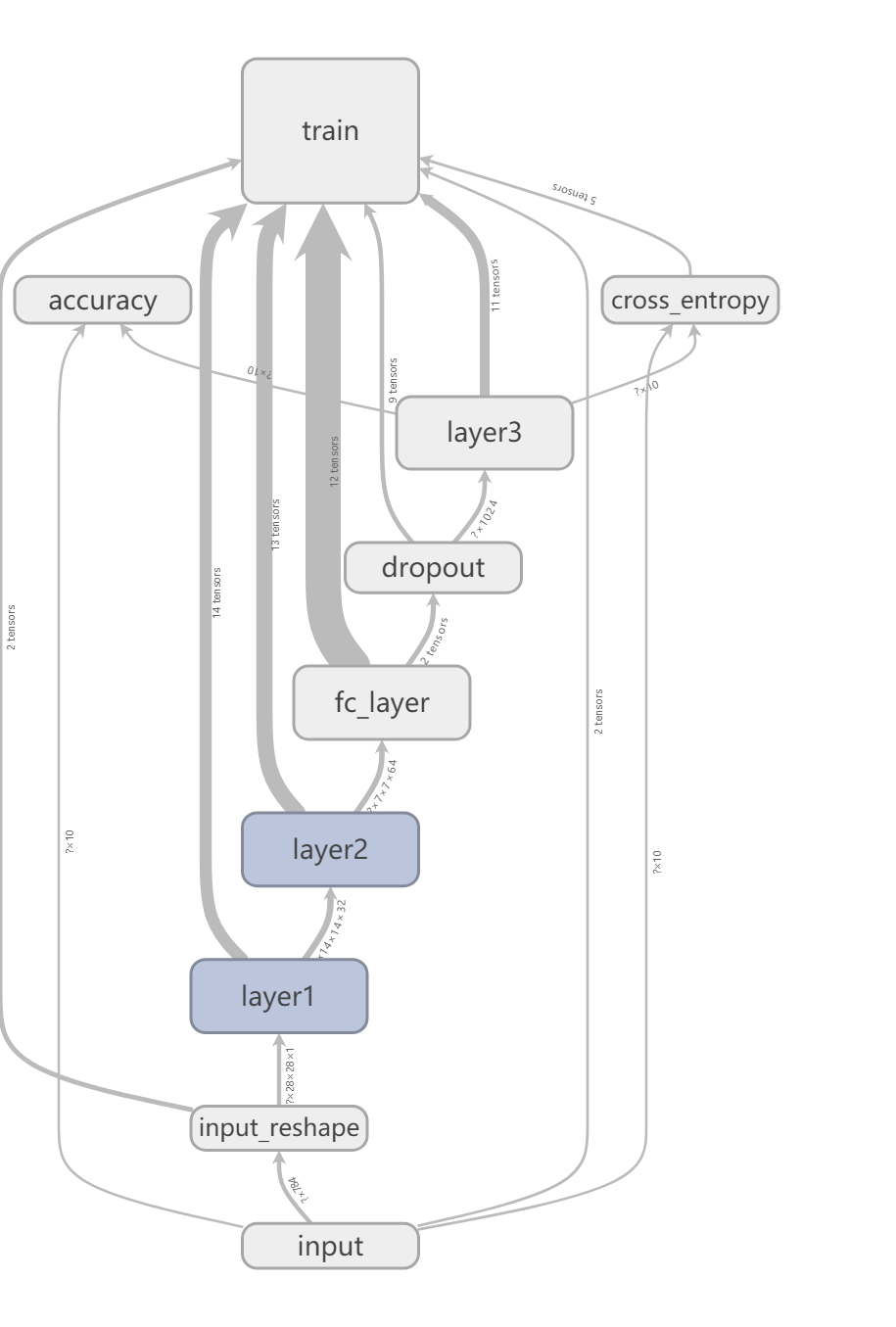
layer1内部结构如下所示
首先初始化权重和偏置参数。然后使用conv2d进行卷积操作并加上偏置,卷积参数为[5, 5, 1, 32], 代表卷积核的大小为5x5, 1个颜色通道,32个不同的卷积核。然后使用relu激活函数进行非线性化处理。然后使用池化函数对卷积的结果进行1/2下采样处理,MNIST数据中图片大小为28x28,经过下采样以后变为14x14。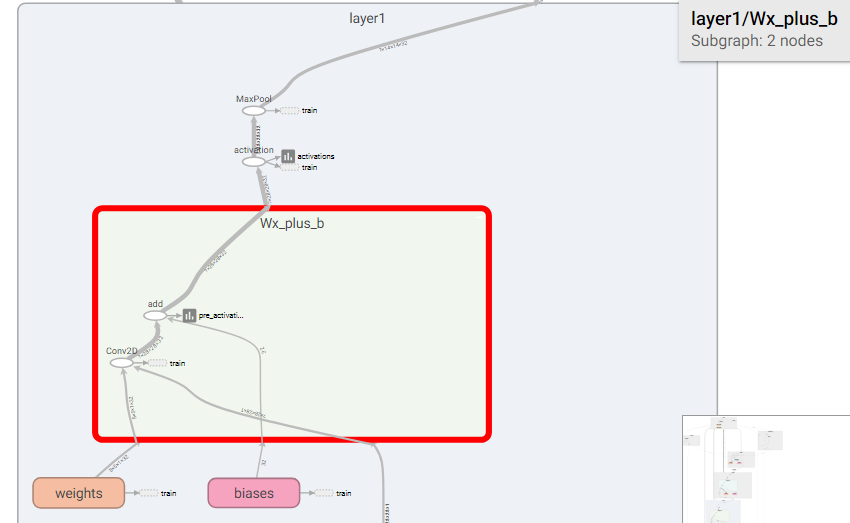
layer2内部结构如下所示
和layer1结构类似,只是卷积参数设置为[5, 5, 32, 64],因为layer1中经过32个不同卷积核的处理,所以每个数据的通道变成了32,另外卷积核的数量变成64,经过池化函数以后,数据由14x14变成7x7。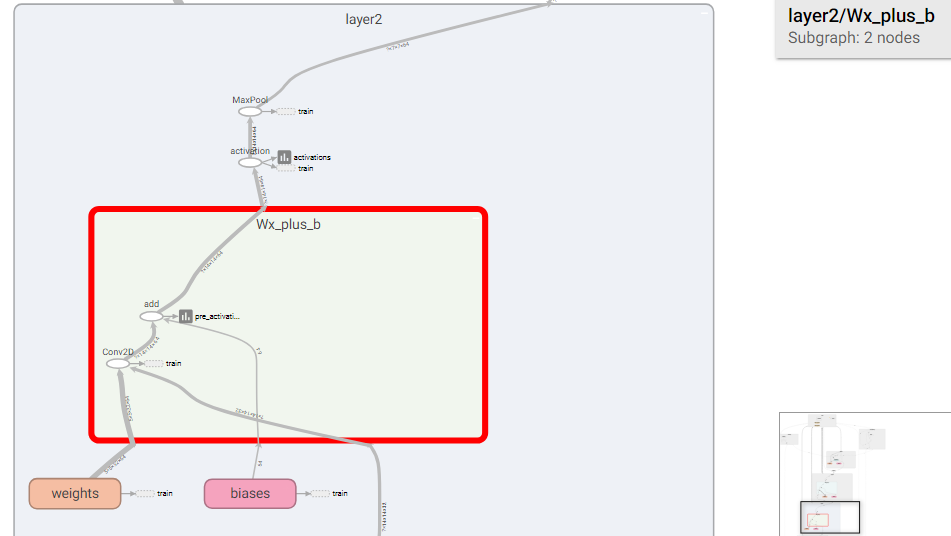
后面再连接一个全连接层fc_layer,输出为1024个隐含节点,并使用relu激活函数。
下面是dropout层,使用keep_prob参数来控制以减轻过拟合。
接下来是layer3层,首先把1024个隐含节点通过矩阵变换转换成10个节点,矩阵变换的参数是权重参数和偏置参数,然后再连接softmax函数,得到对应数字0~9的概率输出。
优化器是Adam,该优化器对定义好的损失函数进行优化。
0x3 高学习率的测试结果
这个时候初始学习率被设置为0.5,从训练集上的测试准确率上来看,准确率是很低的,在0.05~0.15之间来回震荡。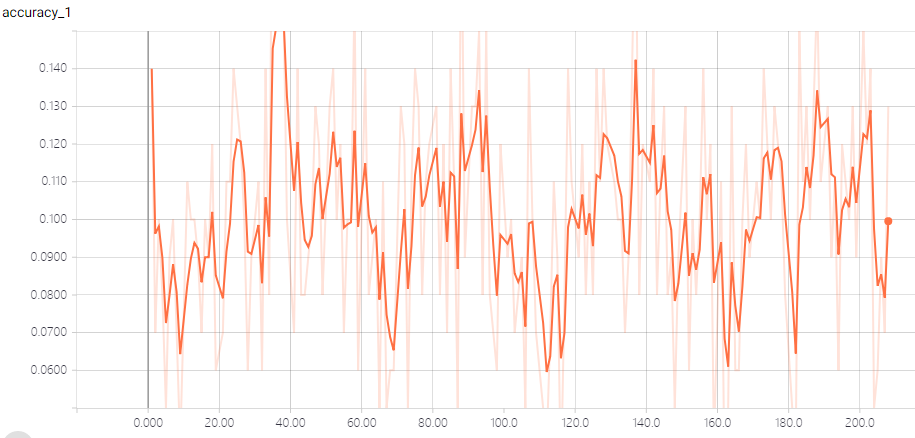
0x4 低学习率的测试结果
这个时候初始学习率被设置为0.001,从训练集上的测试准确率上来看,准确率是慢慢升高的,最后稳定在0.95以上。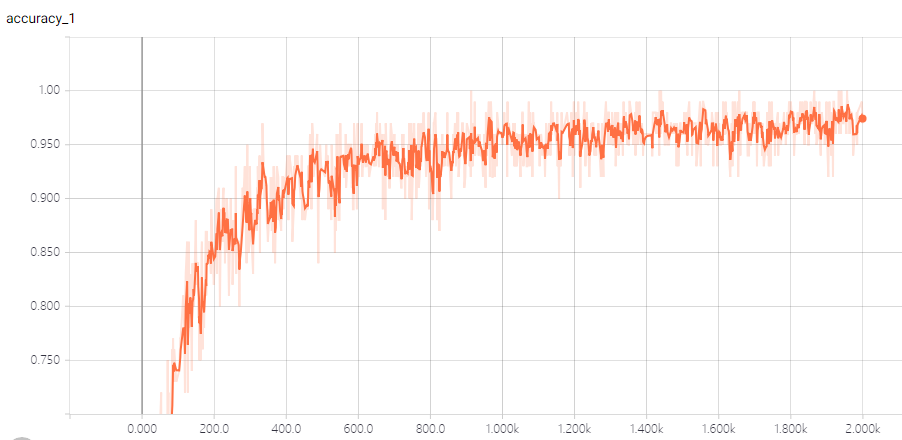
0x5 Adam优化器
通过gdb调试可知,tensorflow中Adam优化器调用堆栈如下。
tensorflow中Adam优化器更新参数的代码如下。
tensorflow/core/kernels/training_ops.cc
算法描述如下
如下所示,虽然在Adam算法中,学习率lr_t是动态调整的,但是也是和初始设置的学习率learning_rate有关,如果learning_rate设置不当,也会影响训练模型的收敛。