0x1 Architecture
RenderScript is a framework for running computationally intensive tasks at high performance on Android. It is similar to OpenCL which is cross platform spec for parallel computation. RenderScript is primarily oriented for use with data-parallel computation. The RenderScript runtime will parallelize work across all processors available on a device, such as multi-core CPUs, GPUs, or DSPs. RenderScript is especially useful for applications performing image processing, computational photography, or computer vision. Android’s doc
Here is the architecture of RenderScript.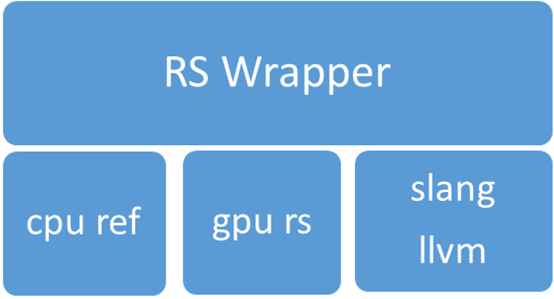
RS Wrapper acts as the wrapper layer for RenderScript, provides the RenderScript api mapping and resource management.
cpu ref is the software implementation of RenderScript on CPU.
gpu rs is the hardware implementation of RenderScript on GPU.
slang/llvm provides the front and backend compiler support for RenderScript’s C99-derived language.
In this article, we will discuss how software RenderScript is suported on multi-core CPU.
0x2 Software Implementation
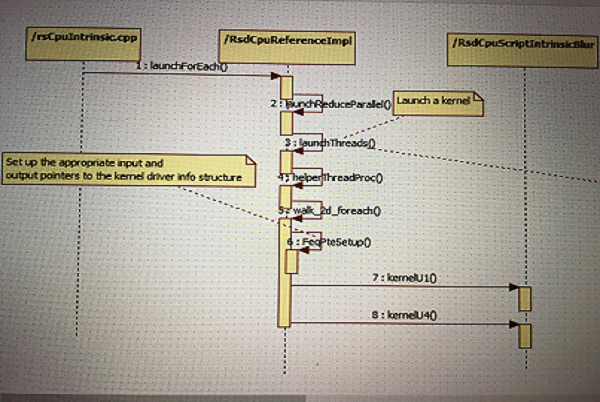
0x21 Create Threads
Create threads for parallel computing based on cpu core’s number
0x22 Thread implementation
Here is the thread’s source code.
dc->mWorkers.mLaunchSignals[idx].wait() is used to wait for the task to be processed.
dc->mWorkers.mLaunchCallback will call the actual processing routine.
dc->mWorkers.mCompleteSignal.set() is used to indicate the processing is complete.
0x23 Launch Thread
dc->mWorkers.mLaunchSignals[idx].wait() is signed in RsdCpuReferenceImpl::launchThreads().
And in RsdCpuReferenceImpl::launchThreads(), we can see mWorkers.mCompleteSignal.wait() is used to wait for the finish of the executing threads.
And the ‘WorkerCallback_t cbk’ is passed in to do the actual processing.
|
|
Here is the code about how launchThreads is used.
0x24 Thread Execution
Each thread setups the task according to the current mSliceNum,
Then it setups yStart and yEnd, then executes kernel from yStart to yEnd.
The kernel is set in RsdCpuScriptIntrinsic::invokeForEach()
or RsdCpuScriptImpl::forEachKernelSetup.
RsdCpuScriptIntrinsic::invokeForEach() is used to setup kernel for Intrinsic.
RsdCpuScriptImpl::forEachKernelSetup() is used to setup user defined kernel in *.rs files.
|
|
0x25 Kernel implementation
Let’s use IntrinsicBlur as the example, in its kernel function kernelU1(), it will produce output pixel from xstart to xend.
the algorithm is based on Gaussian Weights which are initialized in ComputeGaussianWeights().
|
|