0x1 Architecture
From the doc of swiftshader in the following link, we can see the architecture introduction of it.
https://github.com/google/swiftshader/blob/master/docs/Index.md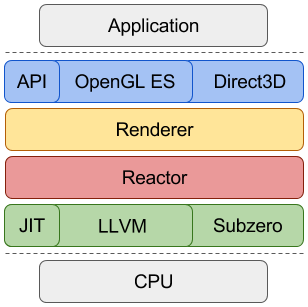
The API layer is an implementation of a graphics API, such as OpenGL (ES) or Direct3D, on top of the Renderer interface. It is responsible for managing API-level resources and rendering state, as well as compiling high-level shaders to bytecode form.
The Renderer layer generates specialized processing routines for draw calls and coordinates the execution of rendering tasks. It defines the data structures used and how the processing is performed.
Reactor is an embedded language for C++ to dynamically generate code in a WYSIWYG fashion. It allows to specialize the processing routines for the state and shaders used by each draw call. Its syntax closely resembles C and shading languages, to make the code generation easily readable.
The JIT layer is a run-time compiler, such as LLVM’s JIT, or Subzero. Reactor records its operations in an in-memory intermediate form which can be materialized by the JIT into a function which can be called directly.
To achieve exceptional performance, SwiftShader is built around two major optimizations that affect its architecture: dynamic code generation, and parallel processing. Generating code at run-time allows to eliminate code branches and optimizes register usage, specializing the processing routines for exactly the operations required by each draw call. Parallel processing means both utilizing the CPU’s multiple cores and processing multiple elements accoss the width of the SIMD vector units.
0x2 Graphics Pipeline
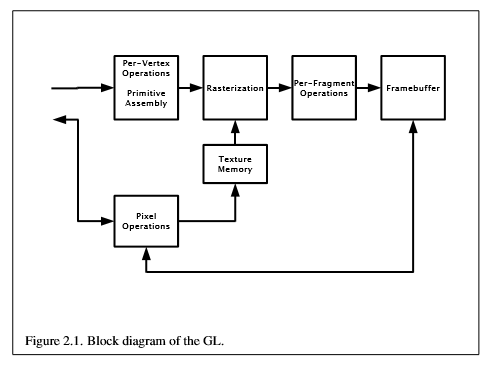
Here is the graphics pipeline diagram from the following OpenGL ES spec. SwiftShader supports the pipeline by JIT through LLVM then executes it on CPU.
https://www.khronos.org/registry/OpenGL/specs/es/2.0/es_full_spec_2.0.pdf
0x3 JIT through LLVM
0x31 GLSL compiler frontend
SwiftShader uses glslang as its glsl compiler frontend, it consumes glsl source code, and produces AST, then outputs its IR with recursive traverse method, here is the IR definition.
Here is the callstack about how IR is generated, it is done by traversing the AST.
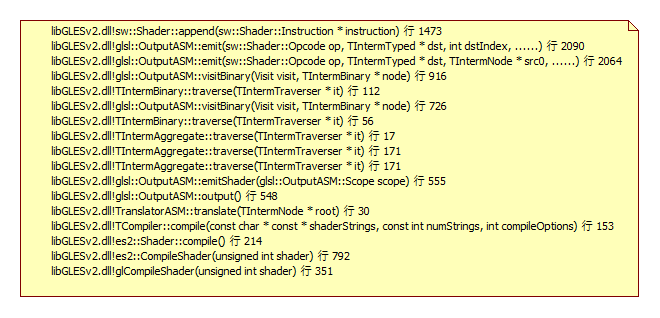
Once IR is ready, swiftshader will consume those IR and generate LLVM IR, some fixed pipeline and graphic state will also be programmed into LLVM IR at the same time.
We will discuss the three processors, vertex processor, setup processor and pixel processor, all the three processor will generate LLVM IR accoring to graphic state.
0x31 Vertex processor
Here is diagram about how vertex processor produces LLVM IR.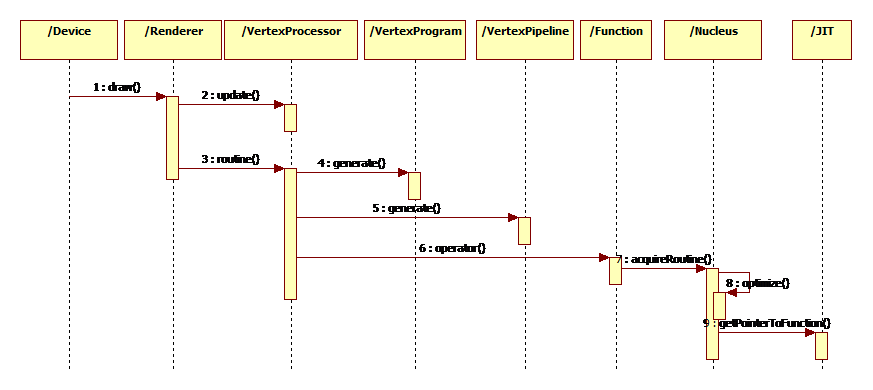
Prepare the draw state
It prepare thes draw state by updating the structe State according to the graphic state.
Generate LLVM IR
Then it generates the LLVM IR with reactor method based on the state which is updated in the previous step.
0x32 Setup processor
The LLVM IR generation process of setup processor is similar to Vertex processor’s.
0x33 Pixel processor
The LLVM IR generation process of pixel processor is similar to Vertex processor’s.
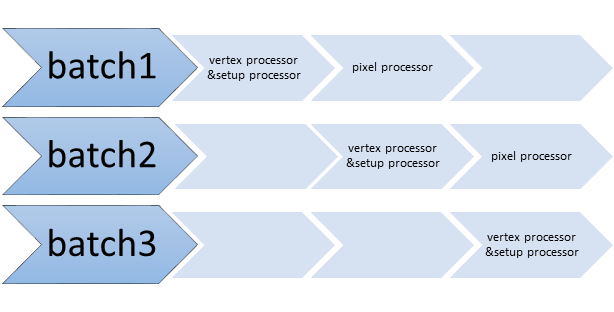
0x4 Multithread
Here is the timeline diagram about how multithread is supported in swiftshader.
It split the draw task into several batches, each batch is executed in one thread.vertex processor and setup processor is executed together, pixel processor is executed after that.
0x41 Task producer.
Task producer produces the task in the main thread, then push the task in the queue and waits for the consumer to get those task for cosuming.
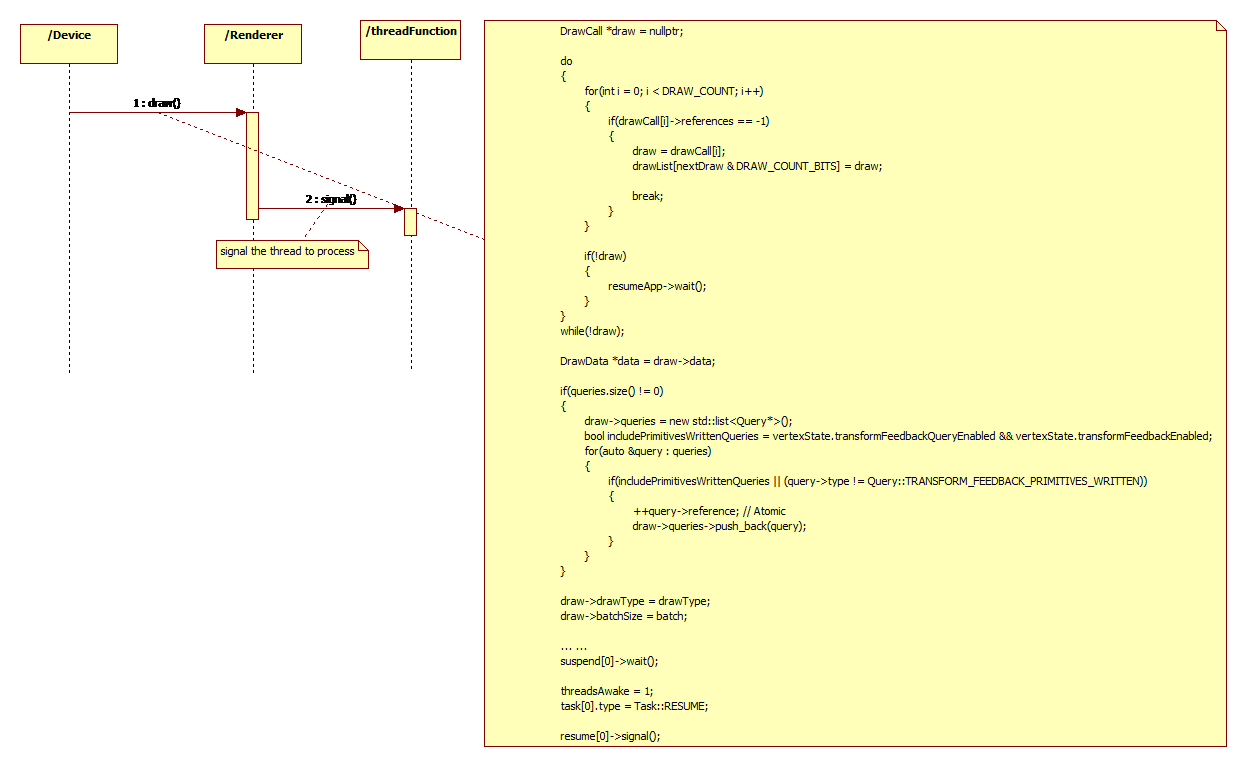
0x42 Task consumer.
Task consumer finds the task in the queue, then exeucute the task in the specific thread.
Here is the diagram about how vertex processor and setup processor is executed in one thread.
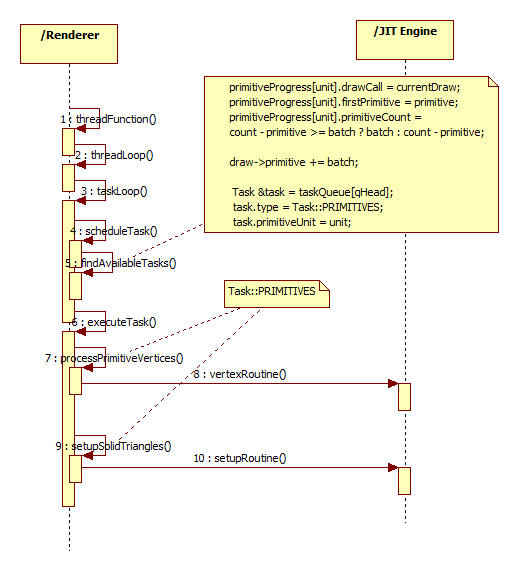
Here is the diagram about how pixel processor is executed in one thread.
![]()